

Last updated: April 23rd, 2024
It’s hard to deny how, at this point, things have changed in AI with the arrival of Large Language Models (LLMs). And much of their success is thanks to in-context learning, the greatest feature of LLMs and the reason why they are sometimes referred to as «foundation models«.
But what is «in-context learning», and why is it so relevant to the success of LLMs and foundation models in general?
A New Paradigm
If we look at how AI has evolved, it rapidly becomes clear how things have changed with the arrival of LLMs, represented by models like ChatGPT, Gemini, or Claude.
And the biggest reason lies in how they broke an important rule that limited AI until that point.
The 1:1 Ratio
Ever since the first AI models appeared, the technology was considered highly specialized. In layman’s terms, all models were highly specialized on a certain topic or task.
This meant that there was an almost guaranteed 1:1 ratio between models and use cases. If you required AI for a new use case, you were required to train an entirely new model for that task.
But why did that happen?
Historically, AI has massively suffered to ‘generalize’. In other words, models worked well as long as the task and the data given were very familiar to the model.
If that wasn’t the case, something we refer to as «out-of-distribution» data, then the model was set for failure. And even if the data was ‘similar’, the model would also fail if the requested task was not the expected one.
Simply put, models did not fare well with new data that wasn’t very close to the things it had seen during training. This fact gave birth to the concept of «Narrow AI», an AI that is only ‘intelligent’ if things are very familiar and constrained.
But what prevented us from breaking this barrier?
A Self-supervised Success
For much of AI’s existence, one theory was commonly accepted but unproven.
If we managed to train models with a sufficiently large dataset and an architecture that could handle so much data without overfitting, we would achieve generalization, or training our very first general-purpose AI model.
However, three things prevented us from taking that step:
- Hardware: Until the arrival of cloud computing and powerful GPUs around 2010, researchers lacked the computing resources to handle large quantities of data.
- Sequentiality: But even though cloud computing was available, gefore the arrival of the Transformer we hadn’t really found a way to train our models at scale by benefiting from GPU’s parallelization capabilities. We had the hardware, but not the software.
- Research: And not only the software was lacking, as we hadn’t found a way to train models at scale without requiring indecent amounts of human effort to label the data.
This meant, in simple terms, that:
- we didn’t have the physical resources and technology,
- our best Natural Language Processing (NLP) models of the time (mainly Recurrent Neural Networks) were sequential and thus extremely inefficient to train,
- and most importantly, the human effort to assemble such a large dataset was absolutely unfeasible.
But with the arrival of the Attention is All You Need paper back in 2017, everything changed. This paper introduced the ‘Transformer’ a seminal architecture that underpins all LLMs today that uses the attention mechanism to process language.
Thus, with Transformer-based LLMs, things took a turn for the magical.
Suddenly, you had a non-sequential architecture (you could run several executions in parallel), that could run on GPUs (it was purposely built for that) and, crucially, it allowed for self-supervised training.
This meant that the actual data included by default the supervisory signal required to train neural networks, avoiding having humans label the entire dataset. Delve into the details of this type of traning and the essense of neural networks and AI in general.
Suddenly, one single model could be used for hundreds if not thousands or millions of downstream tasks.
And with all these elements combined, we finally created our first general-purpose technology, Transformer-based LLMs, thanks to their new unlocked superpower: In-context learning.
In-context Learning, Taking in Knowledge On the Go
Fine, fine. I’ll finally answer what «in-context learning» is. In simple terms, it’s the ability to leverage previously unseen data to perform a prediction and still be accurate.
The Great Change
If we recall the previous section, we mentioned that until the arrival of Transformer-based LLMs, AI suffered greatly with data it hadn’t seen before and that was ‘too different’ from what it had seen in training.
In other words, if the AI bumped into something new, it would most probably be incapable of performing accurate predictions.
Therefore, as the proper name implies, in-context learning is the capacity to learn from new data «on the go».
In more technical terms, it refers to the capacity of an AI model to learn from data without having to update its weights.
For instance, you can now give ChatGPT new data as part of the prompt as context that it couldn’t have possibly known beforehand, and the model will still apply that context effectively. That is the literal definition of what in-context learning is.
And it’s precisely this capacity of LLMs to «learn on context» that makes them so good; it’s like their superpower, because it allows them to perform well in a plethora of tasks, many of which they had not seen during their training.
Put bluntly, with in-context learning AI finally became a general-purpose technology, taking it to a new age that went beyond its specialist days and turned it into a system, or science, that can support humans in many different tasks while maintaining its accuracy.
One model, hundreds of tasks.
And what new capabilities, features, or architectures it unlocked?
Prompt Engineering and RAG
Besides pushing for the creation of foundation models like ChatGPT, in-context learning has created a new field of AI training: prompt engineering.
Simply put, prompt engineering refers to the capability of humans to train models without actually modifying their weights, but grounding them into the task at hand through prompting.
In layman’s terms, prompt engineering is the field that allows humans to train a model for a downstream task by providing relevant context to the prompt and the model using that new information ‘on the fly’.
In case the definition of prompt engineering feels strikingly similar to the definition of in-context engineering, that’s because the sole act of engineering a prompt is just one way to force a model to elicit its in-context learning capabilities.
This information can be provided in two ways:
- Zero-shot learning: Where the model is provided some context in the prompt, but no examples to demonstrate the desired behavior
- Few-shot learning: Where the user provides a few relevant examples of the desired behavior in the prompt that the model then imitates
But prompt engineering isn’t only about providing desired behaviors through examples, it can also literally modify the model’s behavior. Normally referred to as «system instructions» you can lure the model into very specific generalistic behaviors like always being concise with its responses, or always responding in a certain language.
And, fascinatingly, one of the great features of prompt engineering is that it’s non-coded training, as the prompt instructions are delivered through natural language instead of code, meaning that in-context learning indirectly also democratizes AI by allowing non-tech savvy users shape the behavior of the model.
But with in-context learning, we also unlocked the creation of a new type of architecture: Retrieval Augmented Generation, or RAG.
As the proper name implies, RAG architectures augment the generation capabilities of LLMs by providing context through retrieval.
As shown in the image below, the user’s question is used to extract the most relevant context from a database applying semantic similarity over embeddings, and using this new context to enhance the prompt that is eventually sent to the LLM (depicted as OpenAI’s ChatGPT in this case):
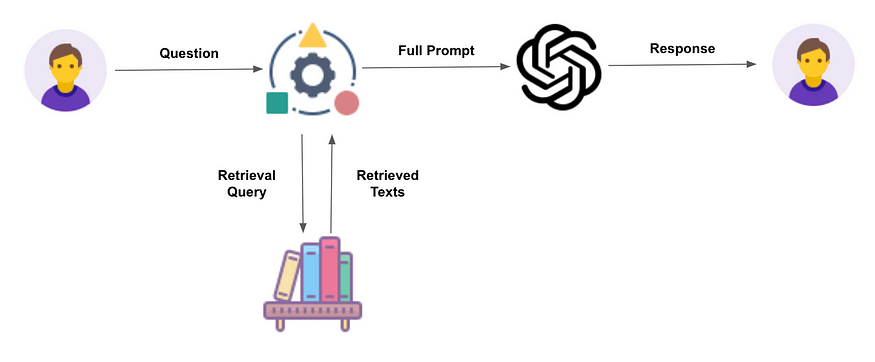
Without getting into much detail regarding RAG, this idea of ‘enhancing’ the prompt in real-time is completely unfeasible without in-context learning, as that capability is what allows the LLM (ChatGPT in this particular case) to use that new context to respond to the user’s question.
RAG is so powerful that is, without a shred of doubt, the most common enterprise architecture used for Generative AI these days. But at this point you may be thinking: we now understand what in-context learning is, but what allowed it to appear in the first place?
Induction Heads, the Secret Behind In-Context Learning
Just like several other incredible capabilities of our current frontier AI models, there is no fully proven explanation as to how in-context learning emerges.
But let me put it this way, we can almost guarantee where they come from, and that is what Anthropic researchers defined as «induction heads».
What are Induction Heads?
Simply put, induction heads are attention heads that develop an extraordinary capability to copy and paste patterns.
You can read a full explanation of the attention mechanism and attention heads, but the gist is that for whatever reason some of these attention heads develop an ability to identify patterns that are essential for the development of in-context learning.
As proven by Anthropic’s research, as induction heads emerge in the model, the LLM’s capabilities for in-context learning dramatically improve.
But what do we mean by «induction heads»?
In very simple terms, induction heads are a circuit that emerges in LLMs that looks back into the context to identify the previous occurrences of the current token, looks into the next token (for sake of simplicity assume that 1 token = 1 word) and attends to it to make it much more likely to be chosen so that the pattern repeats.
So, if the current token is [A] the induction head looks at the previous occurrence of the token in the sequence, looks at the token that came afterward (let’s call it [B]), and encourages the model to ‘repeat the pattern’ by increasing the likelihood that the model predicts [B] as the next token.
For example, let’s say that the current token is ‘Harry’. The attention head will look back in the sequence to find the last occurrence of ‘Harry’.
Once it finds it, it looks at the next token, which happens to be ‘Potter’. Consequently, the induction head will increase the attention from the current token to the ‘Potter’ token so that this increases the likelihood that the LLM predicts ‘Potter’ as the next token, thereby repeating the sequence.
At first, this might seem like a fairly reductionist way of understanding in-context learning. But if you think about it, that’s precisely what applying context to a prediction is, figuring out the patterns in the newly provided context and repeating them.
But is there a way to see this visually?
Applying patterns is applying context
As a more illustrative example, the image below shows the attention scores of the current token (‘:’ in this case) toward all previous tokens, with the more blueish color depicting higher attention. Fascinatingly, the most attended tokens in the sequence are all tokens that were outputted after the same token ‘:’ in past instances.
As these are the most attended tokens, the LLM likely decides to choose ‘_Negative’ or ‘_Positive’ as the next token, which is highly probable it’s going to be the right decision based on the patterns from the context data.

If you look carefully, this is precisely what in-context learning is, a model’s capacity to look at the previous context that it hadn’t seen during training, identifying key patterns, and managing to use these patterns ‘on the fly’ to predict the next token accurately.
In-Context Learning, The Capability that Changed Everything
I hope that by the time you are reading these lines, you are now convinced of the importance that in-context learning has to the recent success of AI, specifically Generative AI.
In fact, looking at how AI has literally sustained the stock market for the last year, one could argue that this is a multiple-trillion-dollar capability.
Additionally, we have seen how in-context learning not only allowed the creation of foundation models, but also democratized AI by allowing the training of LLMs through prompt engineering, a no-code, fully-natural language-based technique to training LLMs.
Finally, we have gained intuition as to how in-context learning is created in the first place thanks to the appearance of induction heads, and we have seen visual proof of this, which I hope helps clarify the very abstract concepts we described in this piece.





