

Last Update: April 23rd, 2024
Note: To Truly grasp the key concepts derived from the following article, I highly suggest you take a look first at my previous post where I dive deep into the attention mechanism.
There’s a critical piece in the attention mechanism that is rarely mentioned but is really important going by the name of the KV Cache.
Today, we are demystifying this concept to delve into its critical importance in the world of AI, while being one of the most controversial elements of all. The reason for this is that, while fundamental to make the entire process feasible, it has serious drawbacks.
Transformers’ Main Bottleneck
In simple terms, the KV Cache is the memory of the Transformer during inference (when it’s predicting words in a sequence), the Transformer being the architecture that uses attention to process language and that has dramatically shifted AI from a specialist technology to a general-purpose one that has taken the world by storm for the last two years.
As we discussed in the attention post, Transformers process language by computing the semantic similarity between tokens (words in the case of text-based Transformers) to calculate the attention scores that each word should be paying to, update each word’s meaning with the surrounding context and, that way, comprehend what the text describes.
But what we didn’t mention was how expensive this process is.
The Quadratic Problem
One of the most powerful features of the attention mechanism is that it has an absolute, or global, context.
In other words, one of the key inductive biases of these models is global attention, which in layman’s terms means that the operator identifies dependencies between tokens in the sequence no matter how far apart they are from each other.
Inductive biases are the assumptions that a certain model architecture does to generalize to new data.
For instance, convolutional neural networks, heavily applied in the field of computer vision to process images, apply ‘proximity bias’, which implies that pixels that are close together are assumed to be related, which makes total sense if you think about it.
In the case of ChatGPT, this means that if we feed the model an ultra-long context with thousands or even hundreds of thousands of words, if two words that are thousands of words apart share a dependency, the attention mechanism should be able to identify that relationship.
For instance, if an important fact was mentioned a long while back and is critical to a more recent prediction, attention’s global context should pick up on it.
The reason why this is possible is based on the fact that the attention mechanism is applied to every single word with every single other word in the sequence.
And in this small fact lies the real issue. Simply put, the attention operator is nothing more than a pair-wise multiplication of all words in a sequence with all other words.
Practically speaking, this means that if we cluster every single attention score (the attention between any given two words) of a sequence of words of length ‘N’ into a matrix, that matrix would be ‘NxN’, which means that for a sequence of length ‘N’, we have N^2 calculations to perform.
This takes us to one of the primary laws in Large Language Models: attention-based LLMs have a quadratic cost complexity relative to the sequence length. Or in layman’s terms, if you double the sequence length, the cost quadruples (or if you triple the sequence length, the cost multiply nine-fold).
But things get even worse.
Layers over Layers
When we think about models as large as ChatGPT or Claude, they don’t have one single Transformer block, they have many.
And in addition to this, as we saw in the attention post, they have multiple heads per layer, so that the model can capture more intricate relationships between words.
This means that we don’t have one single attention matrix, we have multiple of them, and not only across one single layer (across multiple heads) but also over multiple Transformer blocks. This means that as models go bigger in size, the memory requirements literally explode.
For example, for a model that may have a size of around 100 GB (a 50 billion parameter model with 2-byte precision for instance) could end up having memory requierements of multiple hundreds of GB.
And the reason for this is none other than the KV Cache.
The Memory of LLMs
If we watch carefully how LLMs work, we quickly realize one thing: the next-word prediction task is highly redundant.
Shameless Repetition
Let’s take a simple example like «My dog’s favorite place is the…». To compute the next word, the model performs the attention mechanism between all words in this sequence. For example, ‘My’ will most probably attend to ‘dog’ the most, and ‘favorite’ to ‘place’.
Say the next chosen word is ‘park’. But the sequence continues, right? Now, the input sequence to the model is «My dog’s favorite place is the park», but here’s the thing:
Some components used as part of the attention mechanism, mainly the Key and Value vectors of the previous words, are constant through the whole sequence of next-word predictions. However, they are required for every single new prediction due to the aforementioned fact that the attention mechanism forces every word to attend to all previous words.
Consequently, even though we could be well into the thousand consecutive predictions in a given sequence (imagine we have tasked ChatGPT with writing a book) all previous words must still present their Key and Value vectors so that all future words can attend to them.
But as I was saying, they are constant. So what do we do? We cache them to avoid having to recompute them consistently, which would be extremely burdensome for the overall compute budget.
So how does the global process look?
Well, let’s say we are working with the sequence «It was a cold windy morning when I stepped outside, feeling a chill…» where the last predicted word was ‘chill’.
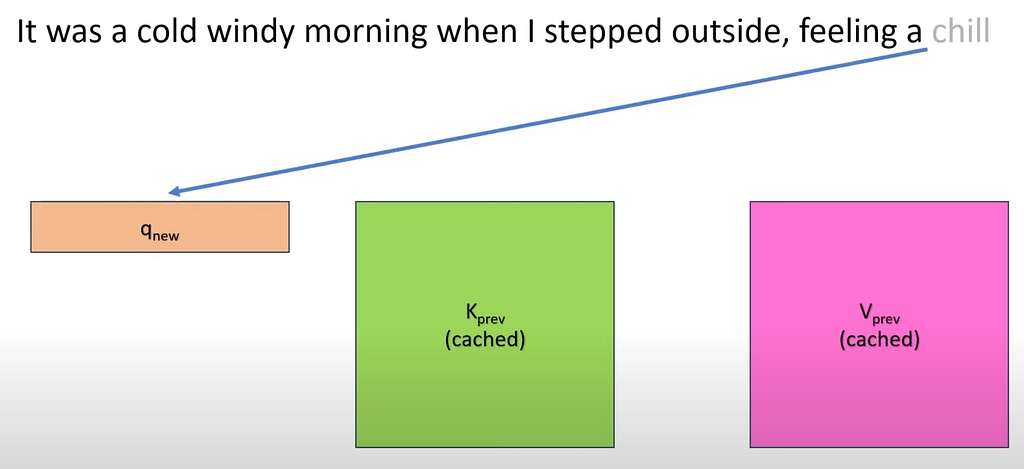
As the attention mechanism goes, chill will generate its ‘query’ vector, and multiply it with all the previous words’ key vectors, and eventually update its value vector with the information provided by all previous words (again, if are having trouble following, this whole process is detailed in the attention mechanism post).
And here enters the KV Cache. Instead of recomputing the Key and Value vectors or previous words, we retrieve them from the memory cache and instantly compute attention with them. In the process, we also generate chill’s key and value vectors to cache them for future words.
To predict the next word, we take the last predicted word, ‘chill’ and compute attention with the rest of the words in the sequence.
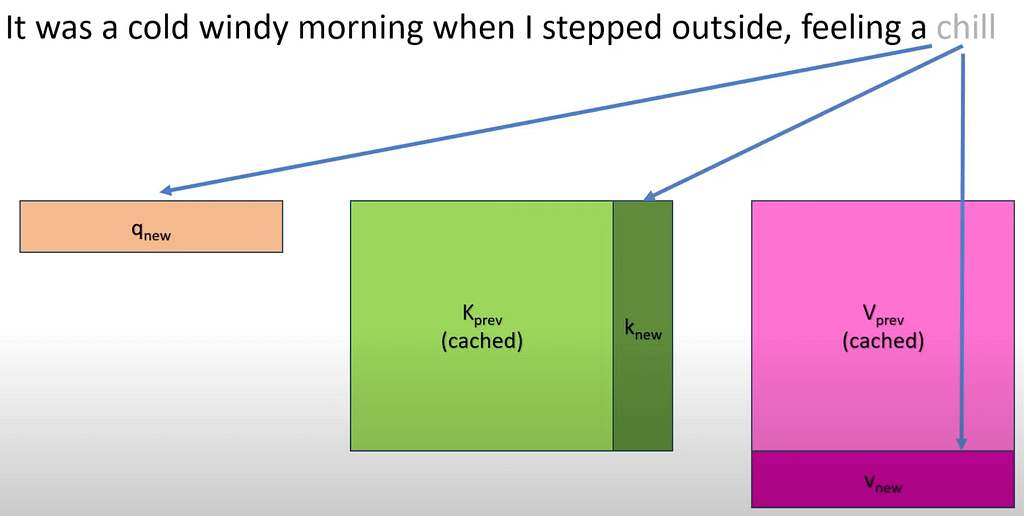
Obviously, this caching mechanism not only comes extremely handy to save computations, but it also reduces the latency of the overall process.
In case it isn’t obvious, as we are caching all previous key and value vectors from previous words, we simply call this the ‘KV Cache’.
Consequently, this KV Cache is what we define as the ‘immediate memory of LLMs’, as the model avoids having to recompute the attention scores of all previous words to predict the next word in the sequence.
Looks rudimentary, but it’s absolutely essential.
Its Growing yet Painful Importance
On one final note, however, as hinted by the introduction, not everything related to the KV Cache was going to be the bells and whistles.
As proven by Hooper et al, as sequences grow longer in size, with examples well above the million-token range already with examples like Gemini 1.5 or Claude 3, the memory allocation required to store the KV Cache explodes in size:
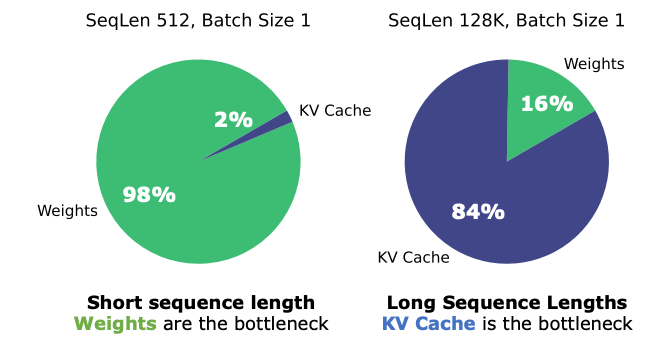
And although these researchers propose a KV Cache quantization (reducing the precision of the KV Cache values) to reduce its memory footprint, there’s no denying that the process by itself is very inefficient.
New architecture paradigms like Mamba introduce the idea of a fixed-size memory, unlike the KV Cache which grows in size endlessly. In that case, the memory size is fixed, so the model is forced to compress its previous context (storing only the relevant stuff).
However, at least at the time of writing, attention continues to be the preferred choice to build Large Language Models precisely due to its unwillingness to compress previous context, allowing it to model language at any desired length thanks to its global scope.
On the flip side, although the KV Cache forces researchers to limit the context window of their models, we are consistently testing new limits, so we could arrive at a point where the context becomes infinite.
KV Cache, Inefficient Yet Still Key
Overall, we have analyzed what the KV Cache is and why it is extremely important to make our current LLMs economically viable.
On the flip side, it is an extremely inefficient way of storing context due to its inability to compress state, but the incredible performance Transformers give has solidified their dominant position despite the growing pains of handling the attention mechanism over long sequences of data.





