

Last update: April 17th, 2024
This article assumes the readers knowledge on embeddings, the attention mechanism, and ultimately Transformers architectures. Please refer to these links for in-depth explanations of every concept.
Large Language Models, or LLMs, have become synonymous with intelligent AI systems. Nonetheless, they are the backbone of all our best AIs, from ChatGPT to Claude, to Gemini.
But rarely do you find a clear explanation of how these systems are created in the first place, which is the objective of this blog post.
Enjoy!
Text-based Intelligence
As the proper name implies, LLMs are Natural Language Processing models, models trained on literally gigantic corpora of text. At the current time of writing, one could claim that these models have been trained with the entirety of text available on the Internet.
But what are they really?
A universal compression
The best way to describe LLMs is as ‘lossy zip files’ as Andrej Karpathy brilliantly described. In layman’s terms, they are a compression of the data they have seen during training.
The reason for that is that LLMs are generative models, models that have been trained with one single objective: maximize the likelihood that the model can regenerate the training data; imitate it.
In other words, they are word predictors.
However, unlike zip files which perform a lossless compression, LLMs do indeed lose some data in the process, which means that this imitation exercise is not always perfect. Far from it.
Consequently, LLMs simply pack all the knowledge they’ve seen during training and learn to generate new sequences that are as similar as possible to the original data. But how do we train an LLM?
LLMs follow a three-step process:
- Pre-training
- Supervised fine-tuning
- Alignment
Let’s cover all three separately.
The Pre-training phase
In very simplified terms, LLMs are word predictors.
Given a sequence of data (text), the model will try to predict what the next word in that sequence is, generating a new sequence of data. This is why LLMs are considered sequence-to-sequence models, they receive a sequence, and they output a semantically related sequence.
Sadly, this effort was tremendously costly initially. But with the introduction of the Transformer architecture and for reasons explained in this link, the AI industry unlocked a massive milestone: scale. Finally, thanks to this architecture, language models could be trained using a self-supervised training method with huge amounts of data at their disposal.
Almost all AI models require a supervisory signal. In other words, they need a ground-truth label that tells them if their current prediction is correct or not. That way, over time, they learn to close the gap between their predictions and what they should have predicted at any given time.
This is how AI learns.
So what does self-supervised learning mean?
In layman’s terms, instead of having to label the supervisory signal manually with considerable human effort, the supervisory signal is provided by the data itself. Imagine if to train a language model you had to manually signal if every single predicted word is correct or not. We are talking about trillions of words, which is not only an extremely expensive feat, but outright impossible.
Luckily, as words follow each other in standard text, the researchers simply had to mask (hide) the next word from the model. Then, once the model predicted which word it was, we could compare its prediction with the ground-truth word (the word that was really behind the mask).
So what did researchers do?
Well, you guessed it, they took the opportunity and fed their models almost any data point on the Internet they could find. As these models grew in size, more data could be fed into them, and we rapidly increased the size of our models to billions of parameters, reaching the trillions at the time of writing.
But one question remains, how do these systems actually generate data?
It’s all probability distributions
All LLMs, be that ChatGPT, Claude, or Gemini, have a fixed-size number of different tokens they can generate.
This list, known as its ‘vocabulary’, is learned during training based on the data and thereby fixed. But here’s the thing, although you’ve probably heard this idea that ChatGPT simply ‘predicts the next word by estimating what the most reasonable continuation to the text sequence is’, well, that’s true and false at the same time.
ChatGPT’s output is not a single word, it’s a probability distribution of the entire vocabulary over the next word. In other words, for every single prediction, ChatGPT outputs a list of its entire vocabulary, ranked by each word’s ‘plausibility’.
To fully understand this whole idea, let’s see an example like «The boy went to the…». In this case, many possible words may be suitable continuations, right?
For that, the model builds a ‘ranking of sorts’ where the best word continuations according to the model are given the highest probabilities. In the example below, we see that although ‘Playground’ seems like the best possible continuation, all other options are valid too, at least semantically speaking.
The layer that generates this probability distribuiton is called the softmax layer, as we apply a softmax operator to calculate the distribution. A softmax takes in a vector and returns this same vector vector but normalized in the form of a distribution. In other words, with all numbers adding exacty to 1.
As we are talking about a child, ‘Playground’, ‘School’, and ‘Park’ appear with higher probabilities than ‘Cafe’ or ‘Hospital’. Still, depending on context the latter two might still work anyway.
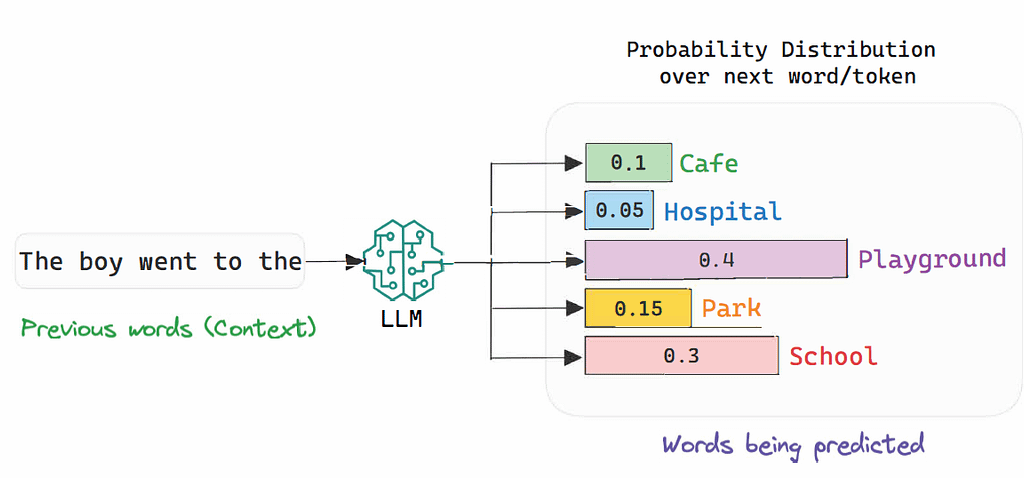
This reason alone explains why we force generative models to output probability distributions instead of fixed words, because we want to account for the variability and non-determinism of human languages.
In other words, humans can construct text sentences expressing the same feelings, thoughts, or ideas, in many ways. Therefore, with probability distributions you account for the uncertainty in the continuation of a text sequence, and more importantly, it allows these models to generate newer continuations, aka allow them to be creative.
But at this point you might be thinking ‘Hold on a second, when I talk to ChatGPT I don’t see a list of words, but one at a time’.
And you are indeed right, but simply because OpenAI abstracts this last step for you and samples a word from the distribution, which is the actual word you then see written on your computer.
Today, OpenAI’s ChatGPT API allows you to retrieve the ‘logits’, the actual probability distributions for every single prediction, in case you need them.
Although I am not going to go into the details, this sampling process can be executed in many different ways, depending on the level of determinism (or non-creativity) you want the model to work on, by adjusting a parameter you will most often see named as ‘temperature’.
And what does this pretraining give us?
It gives us what we describe as the ‘base model’. It’s a model that can reasonably predict the next word in a sequence. However, this model doesn’t work, at all, the same way as ChatGPT.
For example, if you ask it a question, it might give you a question back. Reasons for behaviors like these are many, but in this particular case questions usually follow each other a lot in the Internet (like in listicles) hence why the model is simply replicating standard Internet behavior.
Thus, how do we turn this base model into something you can converse with?
The Supervised Fine-Tuning Phase
At this point, we simply have a «smart bag of words» a ‘thing’ that receives a sequence and returns a reasonable continuation. But ‘reasonable’ doesn’t always equate to useful, meaning that these model will rarely be of any use.
To provide this utility, we need to turn the model into a conversationalist, taking us to a new phase of training, the supervised fine-tuning phase.
At this point, the model has seen basically all text in the world, broadly speaking. Therefore, there’s huge potential and knowledge inside of it, we simply need to find a way to teach the model to elicit this knowledge.
Thus, we build a Supervised Fine-tuning (SFT) dataset, a dataset where data is mainly in conversation form. Here, the objective isn’t to teach the model anything new, but to model its behavior.
In fact, this step in the training is referred to by OpenAI as ‘behavior cloning’.
To allow this, we assemble a dataset, this time in the range of 100k-1M examples (orders of magnitude less from the trillions of examples you can find in the pre-training phase) whose format will be something like:

In case curious, there are plenty of SFT datasets available for free in HuggingFace, with examples such as this one.
As mentioned, the objective now isn’t only to continue to provide reasonable continuations to the input sequence, but now we are maximizing for utility to guarantee not only a reasonable continuation, but a helpful one.
At the end of this stage, your model will behave like a chatbot, with examples such as ‘InstructGPT’. However, even though might be eerily similar to this idea of ‘ChatGPT’, we aren’t quite there yet.
But why?
At this stage, let’s say the model is ‘too helpful’. Hold on… since when being ‘too helpful’ is something to be wary off? Well, think about it. These tools are accessed by millions upon millions of people… people that might have good or bad intentions.
Consequently, just like an LLM can help a student write better or perform faster research, it can also help a terrorist learn assemble a bomb.
Although you can make the case that this information was already available in the open Internet, LLMs simplify the research process a lot. Simply put, really bad recommendations are simply a question away from bad actors.
Therefore, we add an extra stage, probably the most controversial: Alignment.
The Alignment Phase
As mentioned, at this stage the model is pretty much a conversation-ready AI. It has been optimized not only to be accurate, but also helpful.
Now, it’s time to optimize for ‘safety’. In other words, we want to make the model «aware» of what things it can say, and in which cases its knowledge should be suppressed.
As you may imagine, this is a very, very controverial action, as there’s a really thin line between suppressing objectively wrong behavior and censorship.
To perform this alignment, we first need to build a «human preference dataset». These datasets aren’t focused on tailoring behavior, but improving the model’s decision-making. In most cases, they are built following a «better/worse answer» format.
Building this dataset is by far one of the most expensive parts of the training pipeline, due to the high expertise required from the experts and the sheer amount of examples they need to handle, being almost like a moat for cash rich tech companies in comparison to open-source researchers.
For any given question, the dataset will display several different options (most times just two) and the model has to decide which option is best:

Consequently, the model here needs to learn to choose the best option in detriment to the worst option. To optimize the model using this dataset, we have two options:
- RLHF: Reinforcement Learning from Human Feedback is a technique that teaches the model to choose the option that maximizes the reward. For this reason, this technique requires an additional model, usually equal in size to the model being trained, to act as the reward model.
- DPO: Direct Preference Optimization is a relatively new technique (from last December) that avoids having to create an additional reward model by parametrizing the reward implicitly. In layman’s terms, the model uses its own responses as rewards, making the process considerably cheaper and as effective as RLHF.
There’s another very recent option known as the Kahneman-Tversky Optimization that doesn’t require a human preference dataset, as this method doesn’t require a better/worse pair for every prompt, but simply a ‘it’s fine/it’s not fine’ label to every response (known as a weak signal), a label that can be provided by other LLMs. Proven at scale, this is without a doubt the best option in terms of costs.
And it’s at this point, after the laborious alignment stage, when we get the ChatGPTs, Geminis, and Claude 3s that are now made available to users.
Congratulations, you now know how to build an LLM.
LLMs, the AI Models that Changed Everything
In this lengthy post we have seen a step-by-step guide to building Large Language Models, the pinnacle of AI’s state-of-the-art today and the backbone for most AI applications.
This is part of a series of blog posts that aims to democratize AI with simple-to-understand blogs tailored to both technical and non-technical backgrounds, with the links at the top of this blog being the predecessors to this blog in the series.
On a final note, LLMs are sometimes referred to as Foundation Models, AI’s first general-purpose technology, due to their insane in-context learning capabilities that allow them to generalize to new data and serve as foundation to most of use cases for AI being implemented today. Read the previous links in case you want to dive deep into those concepts!





