

Last updated: April 2024
In fields like AI, where everything seems to move so fast, it’s critical to identify the things that remain. Models pass and models improve, but some breakthroughs are sticky enough to become ubiquitous. And one of those things is the concept of Mixture-of-Experts, or MoE.
MoE has become so common that it’s really hard to find a new Large Language Model, or LLM, that isn’t a MoE at this point. GPT-4, Gemini 1.5, Mixtral 8x7B, or Jamba are MoEs, just to name a few.
But first, what is a MoE, and why are they so important today?
A Story of Sparsity and Knowledge
In simple terms, MoE is an AI training technique that essentially ‘breaks’ certain parts of a neural network, often an LLM, into different parts, called ‘experts’.
The reasons for this are two-fold:
- Neural networks are notoriously sparse, especially at one specific layer
- Neurons are polysemantic by design and suffer greatly to elicit knowledge stemming from too different topics
When underfit models are the standard
Unbeknownst to many, Neural networks are actually too big for most predictions they make. Even though the entire network is run for every prediction, only a very small fraction of the model actually contributes.
For example, ChatGPT, even though it is forced to run the entire, gigantic network to predict every single new word, which is an enormous computational effort, only very specific parts of the network will activate in order to help predict the new word.
In other words, they have a huge amount of unnecessary computations, making our bigger LLMs some of the most inefficient and energy-consuming systems in the world.
Today, the AI industry, dominated by LLMs, consumes more electricity than entire small countries.
But besides uncontrolled consumption, having the entire model run for every single prediction also has important performance implications.
‘Know it all’ Neurons
If you’re familiar with neural networks, you will probably have heard of the idea that neural networks are infamously opaque. What this means is that it is extremely hard, or outright impossible, to discern the reasons behind most of their predictions, especially when referring to huge neural networks like LLMs.
The most common way of trying to figure out how they work is by ‘probing’, where we study the intermediate activations (the values that neurons inside the network take for a specific prediction) and try to analyze if they give us intuition as why the neural network predicted what it predicted.
Sadly, through this method, we run into a huge wall: polysemanticity.
This weird concept is a really fancy way of saying that neurons are not monosemantic, aka they do not specialize in one single topic, but many of them. And importantly, semantically unrelated.
For example, one single neuron out of the billions a neural network has might activate every time the input topic concerns Shakespeare, but also when the topic is about Jamaican skateboarding.
Not much relationship between them, right?
This, besides making neural networks really hard to explain, is also not ideal as neurons have to become proficient at various topics that have little to nothing to do with each other. Imagine you had to become an expert in neuroscience and Peruvian forests at the same time, it’s going to be a hard task.
Without deviating too much from the topic at hand, mechanistic interpretability is the field that is trying to ‘make sense’ of AI models. A very promising path is achieving monosemanticity by combining neurons.
While a single neuron is always polysemantic, combining certain neurons elicit very specific topics, to the point that if we force the activations of those specific neurons, the model outputs predictable behavior, even though we have only achieved this at very small scale. For more info on this, check here.
Consequently, with such a broad knowledge spectrum, these neurons suffer to elicit knowledge. Even worse, the learning curves might contradict each other, and learning more about one topic may impact the neuron’s capacity to elicit knowledge on the other.
Imagine you are forced to become an expert on contradicting theories, like capitalism and socialism. Many pieces of information from one will contradict the other, which could provoke a knowledge collapse that causes you to become essentially incapable of talking about one or the other.
So, what if we could use a technique that eliminates, or at least reduces both issues? Well, this is what Mixture-of-Experts intends to solve.
Mixture-of-Experts, the Triumph of Conditional Computing
Although a decades-long concept, Mixture-of-Experts become prominent in the field of AI thanks to this seminal paper by Google Brain and Jagiellonian University researchers.
The idea is simple: Assuming the sparsity of neural networks, especially at the feedforward layers (we will get there in a minute) so common of architectures like the Transformer (ChatGPT, Gemini, Sora, etc.) we essentially ‘break’ these layers into smaller groups of identical shape we call ‘experts’.
Additionally, we add a gate, known as the ‘router’, in front of the layer that will choose, for every prediction, which experts are queried, while the others remain silent.
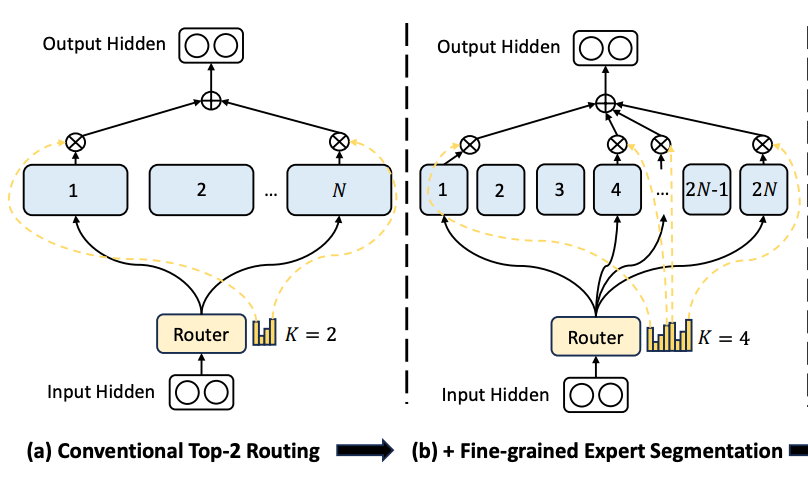
A very famous example of such a model is Mixtral of Experts, or Mixtral-8x7B, a model by French company Mistral that despite having almost 50 billion parameters, only 12 of them run for every prediction, achieving efficiency gains that allow costs to drop by 4-fold and inference speed to increase 6-fold.
In this particular case, is composed of eight different 7-billion parameter models, two of which are chosen for every prediction (hence the 4-fold efficient improvement). But Mistral isn’t the only company using Mixture-of-Experts, with previously mentioned examples like Google, OpenAI, Meta, or AI21.
And what are the main benefits of mixture-of-experts?
Specialization as dogma
Based on the previous issues we have described, the reasons for MoE models to exist become apparent. Our objective is simple, achieving conditional computing, meaning that we can have some sort of ‘decision-making power’ over how much of the neural network actually runs.
A very, very recent approach to conditional computing is Mixture-of-Depths. Here, instead of partioning the depth of the model, we focus on giving the model the capacity to decide the computation dedicated to each input. It’s orthogonal to MoEs, in the sense that they are not substituting each other but are complementary techniques for more efficient and scalable inference.
For starters, we can decide how many experts we want our model to be broken into. Additionally, we can impose how many experts will the router choose for every prediction.
But, technically speaking, what does MoE really mean in practice? Well, it’s an alternative to one of the most common layers in neural networks these days: the feedforward layer (FFN).
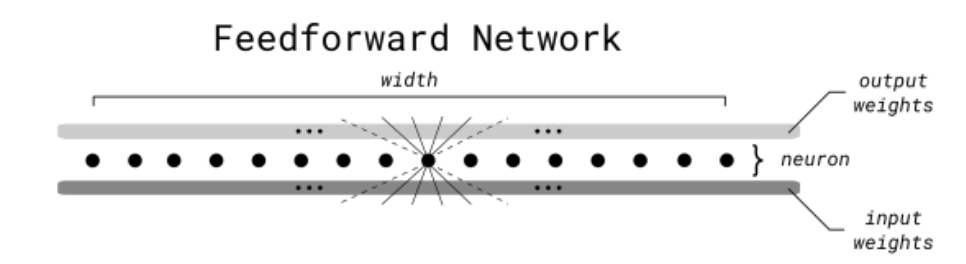
As we discussed earlier, LLMs like ChatGPT are made up of two types of layers, attention layers, covered in this other blog I wrote recently, and FFNs.
But what is the role of FFNs?
FFNs project these vectors into higher dimensions temporally to unearth nuances in data that are otherwise hidden. This has proven absolutely key to the success of these models, but comes at a cost.
Despite being extremely costly to process, there’s highly conclusive evidence to suggest that FFNs are extremely sparse.
Due to the insane amount of parameters they have in the effort of increasing the dimensionality, that means a whole lot of computations. Lunch is never free.
In fact, according to Meta, they can imply up to 98% of the total computation in a forward pass (prediction) of an LLM.
Adding to this, while the amount of parameters is huge, the vast majority don’t activate for each prediction, so while they are computed as part of the process, they don’t “contribute” to the actual next-word prediction.
In other words, you are computing as if the entire network would participate, only to have an embarrassing fraction of it (sometimes in single-digit-percentage numbers) actually help in the task.
And here comes Mixture-of-Experts, where an expert is, you guessed it, a small fraction of the parameters in an FFN. Functionally speaking, in broad terms, for every prediction a router chooses what experts will participate in the prediction.
And why do we call them experts?
Instead of querying the entire group of experts at once only to have a few respond, the router actively chooses those that it predicts will know the answer. And, as this is done from the very beginning, the different experts become specialized in different topics.
In more technical terms, what is happening is that the input space gets ‘regionalized’. If you picture the ‘complete space of possible requests’ that a given LLM may receive, each expert becomes more savvy in certain topics, while other experts become more knowledgeable in others.
Instead of having one single ‘know it all’ expert, you create a group with their specific areas of expertise. However, one of the issues we will now delve into is the knowledge redundancy, or knowledge overlap.
Thus, MoE models are simply equivalent to their standard versions but substituting the FFN layers with MoE layers, as shown below:
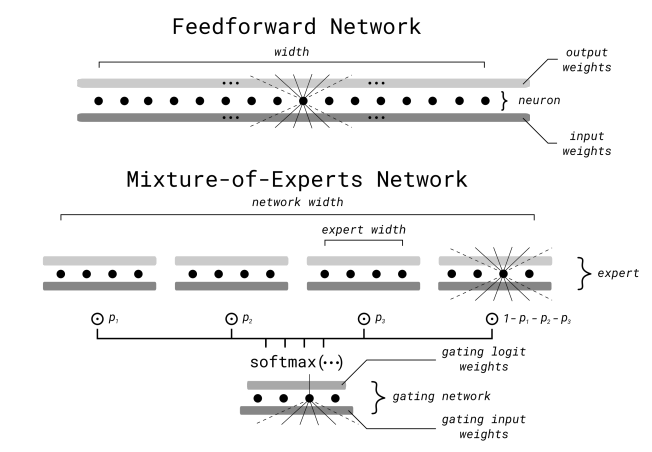
In some cases not all FFN layers are substituted by MoE, with models like Jamba having multiple FFN and MoE layers.
Consequently, they work as follows:
- An input arrives at the gate. This gate is nothing but a softmax that takes this input and outputs a classification of all the experts categorized by their assigned probability.
- Using the above example, for four experts, you could have the following list: [Expert 1: 25%, Expert 2: 14%, Expert 3: 50%, Expert 4: 11%] meaning that for that input in question, Experts 3 and 1 are chosen to activate.
But practically speaking, what are we obtaining by doing this?
In simple terms, as these experts have existed since the very beginning, during training each one becomes more specialized in certain topics, with other topics being learned by others. Consequently, each expert becomes much more proficient in their specialized topics.
Besides the obvious benefits of higher computational efficiency, MoEs also open the door to a much higher degree of neuron specialization (the name ‘expert’ has a reason behind it). Circling back to the issues we described earlier, neurons with highly contradicting topics may suffer to elicit knowledge when queried.
For that, having experts specialized in diverse topics may ‘facilitate the job’ for the neural network as a whole to prove its knowledge.
Overall, considering the obvious benefits of MoEs, everyone seems to have jumped aboard the ‘MoE hype train’.
But despite the undeniable successes, these architectures suffer from two illnesses: Knowledge hybridity and knowledge redundancy.
- Knowledge Hybridity occurs when each expert ends up handling a broad range of knowledge due to the limited number of experts. This broadness prevents experts from specializing deeply in specific areas.
- Knowledge Redundancy occurs when different experts in an MoE model learn similar knowledge, which defeats the point of partitioning the model in the first place.
Toward Hyperspecialization
Although fairly new in the «grand scheme of things», a recent trend has been to search for hyperspecialized models, aka models with dozens of experts.
Today, the standard approach is having your network divided into 8 experts with 2 experts chosen for each prediction. However, besides the fact that the number of expert combinations is fairly small, these experts tend to absorb similar knowledge between them, increasing the redundancy of experts.
One interesting trend recently is to add the concept of ‘shared experts’ with examples like DeepSeekMoE family from DeepSeek.
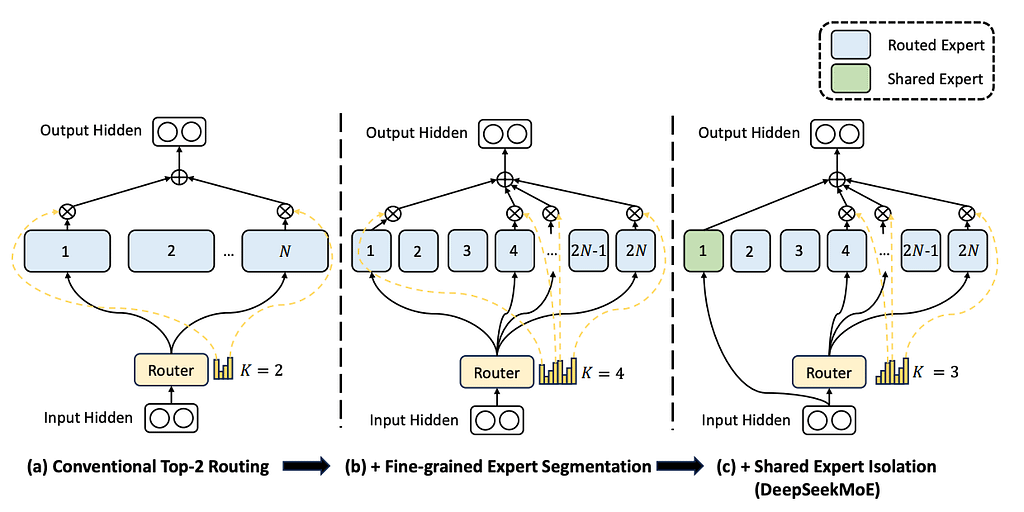
Here, ‘k’ experts are fixed, in the sense that they always run for every prediction. This ‘shared expert’ or experts capture the broad knowledge, while the hyperspecialized experts, which can reach up to 64 for this particular model, capture more fine-grained knowledge.
This way, you ‘fight off’, or at least minimize, the aforementioned issues of standard MoEs, knowledge is less redundant as experts are much more specialized, while the ‘broader’ data is captured by the shared experts.
Although not yet fully proven at scale, these models exhibit highly promising results to become a standard above the usual MoE models, but it’s too soon to jump to conclusions.
Mixture-of-Experts, Here to Stay
As I said at the beginning of this long post, things come and go, but seminal breakthroughs stay, and Mixture-of-Experts is one of them, independently of the form it eventually takes.
In summary, we have reviewed the common issues that LLMs run into and how MoE helps to solve them, hence explaining their ubiquitous presence in frontier AI these days.
Want to trace back to the roots? Check my simple introduction to AI here.





