

Last update: April 23rd, 2024
This is part of a series describing the key principles underpinning the current AI revolution. To fully understand this blog post, I highly encourage you to take a look at the blog post about Large Language Models (LLMs) and Transformers.
As we discussed in the previous blog post about Large Language Models, what they are, and their huge importance in AI’s current state-of-the-art, these foundation models have become synonymous with cutting-edge AI implementations and often-overhyped discussions about the proximity to achieving Artificial General Intelligence, or AGI.
But while AGI isn’t coming to our lives any time soon, LLMs are indeed seeing a great enhancement going by the name of multimodality, turning our frontier models from text-only to models that handle multiple data types at once, going by the name of Multimodal Large Language Models, or MLLMs.
Today, examples like ChatGPT, Gemini, or Claude, among many others, are no longer LLMs, but MLLMs, thanks to the fact they can process text, images, and in some cases, video.
But first, why do we need multimodal models?
The Need for Multimodality
In an ideal world, everything would be described or provided in text. That way, we would only need LLMs to perform any task. The truth, however, most data is not text-based. In fact, we have data coming in the form of images or video, audio, speech, and many other examples.
In fact, some of the most relevant problems that AI can solve for us require multimodality.
For instance, if we think of a virtual assistant, we might want to ask it about a certain scratch or inflammation you have developed in your hand. Or you might simply want it to describe a new meal you’ve seen while touring Asia.

Thus, how do we actually assemble an MLLM?
Breaking down the Model
In simple terms, most common MLLMs today comprise two elements, an LLM, and an encoder of another modality. Let’s break this down.
LLMs, the backbone of frontier AI
As we thoroughly explained in the previous blog on LLMs, these models are sequence-to-sequence models that take in input in the form of text and return a statistically probable continuation to that sequence.
In other words, by performing a next-word prediction, they are capable of generating eloquent text. And ever since ChatGPT was dropped in 2022, LLMs have become a productivity tool used by more than 200 million users around the world, turning the app with the same name into the fastest-growing digital consumer application in history.
Specifically, their remarkable capacity to imitate reasoning and enhance creative processes has opened the question of whether these systems can be used as backbones for more complex and diverse use cases that go beyond the mere use of text.
But to do so, we need an extra component.
Encoders, the Bridge to Other Worlds
If not obvious by now, LLMs only work with text (and in some cases code due to its similar nature to natural language). Therefore, to tackle other data modalities like images or even video, the model requires another component: an encoder.
The reason for this is that, as we discussed in the Transformer post, LLMs are decoder-only Transformers, meaning they use a trick to encode data.
But what do we mean by ‘encode data’?
Encoding the input sequence, be that words for text or pixels for images, revolves around the idea of transforming these inputs into lists of numbers known as vector embeddings, a representation of the input in the form of vectors that capture their semantic meaning.
In the specific case of LLMs, as we described in the Transformers blog post, they have embedding look-up matrices, matrices that take the tokens from the input sequence and retrieve their specific word embedding from the matrix. In other words, the embedding transformation is learned as part of the training, not really applied during inference.
This is done as a cost-effective way of encoding data with having to actually run an encoder network every single time.
Encoding data can take two forms: one-hot, or dense. One-hot encoding simply turns every word into a list of numbers where all numbers except one are ‘0’, and one of them is marked as a ‘1’:
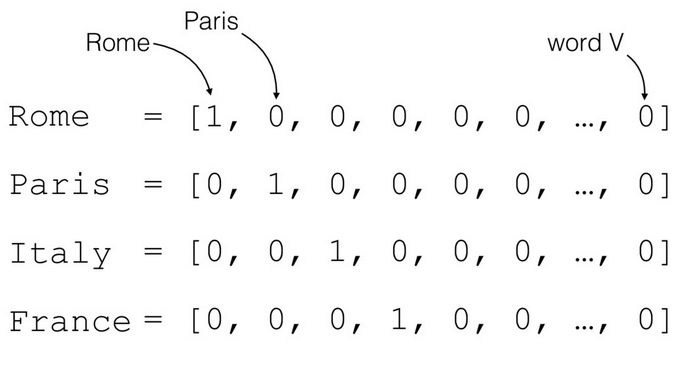
But in the case of MLLMs, the embeddings are ‘dense’, meaning that they take values in a way that similar concepts in real life have similar vectors (magnitude and direction) and vice-versa:

And to do such a thing, we need an encoder, another Transformer-based architecture that takes the input data and transforms it into vector embeddings. For instance, if the encoder takes images, the model will turn the image into an ‘image embedding’.
No matter the data format, the objective is always the same: Generate a vector space where similar concepts in real life have similar vectors and dissimular concepts are turned into vectors that are pushed apart. This way, we turn the concept of understanding the semantics of our world into a mathematical exercise; the closer two vectors are, the more similar their underlying concepts are.
And here’s the key thing, this process can be done for other types of data besides text, like images.

But with images, things can get tricky.
We not only want the image embedding to classify similar images (for instance, husky images) into similar vectors, but we also want them to be similar to a text description of the same image. For example, as seen below, an image of a wave and a text passage describing the same scene should have similar vector embeddings despite being from different modalities.
To achieve this, labs like OpenAI created models like CLIP, which created these mixed embedding spaces where images and text describing semantically similar concepts would be given similar vectors.
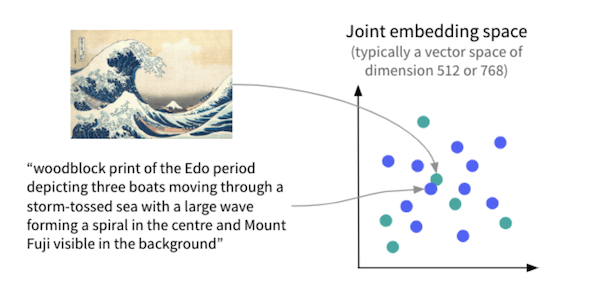
Thanks to models like CLIP, machines can now process images and understand their meaning.
Another popular method to train image encoders is Masked AutoEncoders, or MAEs. In this case, the model is given an image with some portions of it masked (hidden) and the model has to reconstruct it. These encoders learn very powerful representations, as they have to learn to understand «what’s missing» or «what’s hiding behind the masked parts».
However, CLIP encoders are much more typical in the case of MLLMs due to their inherent connection to text.
But then, if we want to create a model that processes both images and text, like ChatGPT, how do we actually assemble such a system?
Types of MLLM systems
There are basically three ways you can create a Multimodal system.
From Tools to Real MLLMs
The three categories all create MLLM systems, but only two of them could be considered real MLLMs.
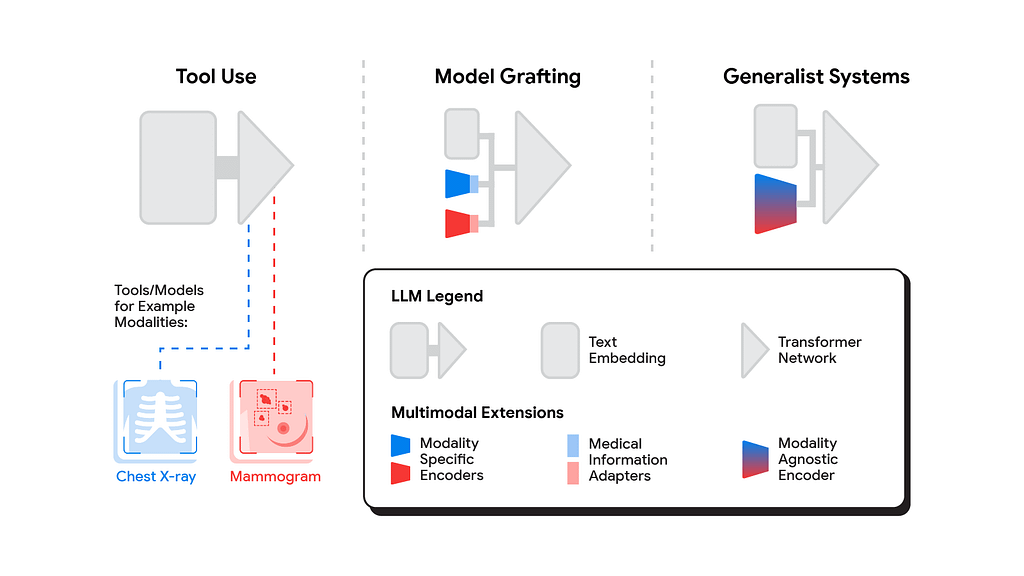
- Tool-Augmented LLMs: This involves combining an LLM with an exogenous system that can process other data types. These systems aren’t considered Multimodal LLMs, because we are simply augmenting the capacity of the LLM by combining it with another model or tool. An example of this is ChatGPT for speech/audio processing, as the actual LLM is connected to two separate models, a Speech-to-Text and a Text-to-Speech model. Thus, whenever the model receives audio, it sends it to those systems for processing, it’s not the actual MLLM processing the data.
- Grafting: This process involves the creation of an MLLM by stitching together two already-trained components: the encoder and the LLM. This is by far the most popular method among the open-source community due to it being highly cost-effective, as you usually simply need to train an adapter to connect both pre-trained models.
- Native MLLM (Generalist Systems): This approach is the one used by the most popular – and cash-rich – AI research labs. It involves training both the LLM and the encoder from scratch while connected from the very beginning. This yields the best results but is the most expensive by far. GPT-4V (ChatGPT), Grok 1.5V, Claude 3, or Gemini are among the examples that follow this method.
We could add one last method, which is the creation of an MLLM without actually using a separate encoder, with examples like Adept’s MLLMs. However, this is a very uncommon approach.
So, be that approach 2 or 3 (as mentioned, number 1 isn’t really an MLLM model but an MLLM system), how do they work?
The MLLM pipeline
We are going to focus on the most common MLLM approach, an image encoder and an LLM, for models that can process both images and text. However, let me be clear that by switching the encoder you can also work with other modalities, like using and audio encoder for audio. The LLM is always kept due to their capacity to converse with the user and, in some limited cases, reason complex tasks.
Whenever we send data to an MLLM, this will usually be in two ways:
- Just text: In this case, we only provide text to the model, so we simply want it to behave like a standard LLM. To see a full review of the steps occurring in this case, read the blog post about Transformers here.
- Text and images: In this case, the model receives an image and a text request over the image. We will focus on this example now.
We can use the following example of Sphinx, an open-source Multimodal LLM.
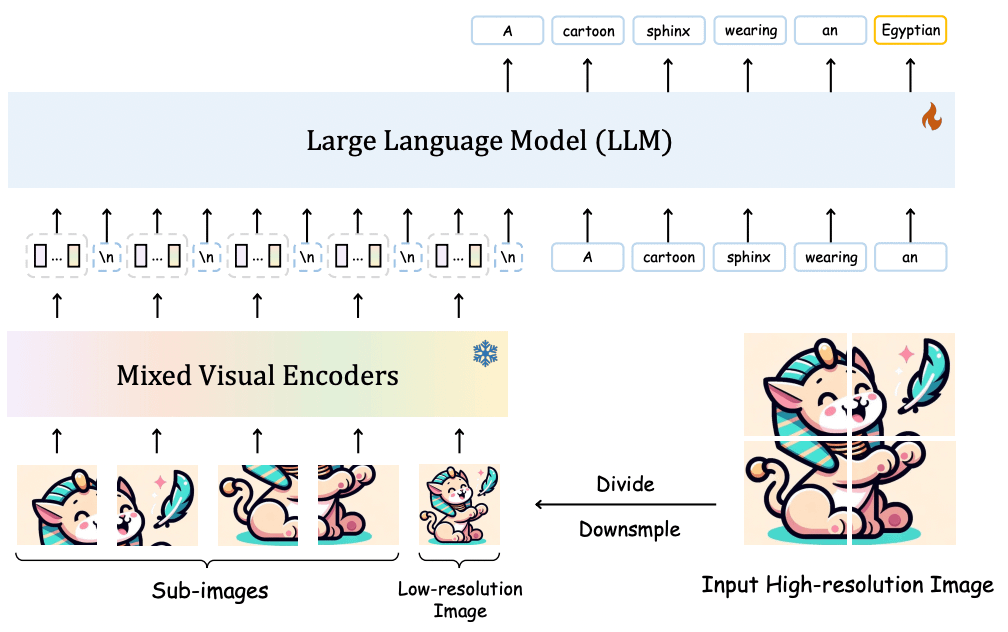
- First, we have the data, a cartoon image of a sphinx, and a text description of that image, and we want the MLLM to see both and be capable of describing what the image portrays.
- The image is then partitioned into patches (in this case they also create an additional patch that represents the complete image in lower resolution)
- The patches are then inserted into the image encoder, which processes them and generates their corresponding patch embeddings. Each embedding captures the semantics of its patch.
At this stage, one of two things will happen. If you are following a grafting method where the image encoder and the LLM were pre-trained separately beforehand, a common approach is to use an adapter which translates the image embeddings into the embedding space of the LLM. If you are using a generalistic approach, the image encoder already learns to generate valid embeddings for the LLM.
- At the same time, the text caption of the image is also sent into the model. In this case, the text sequences follow the pipeline we described for Transformer LLMs here (tokenization, embedding look-up, positional embedding concatenation, and insertion)
- The LLM now takes all inputs as one single sequence and uses them to generate the new sequence, considering both the information provided by the image and the information provided by the text input.
Final Thoughts
Multimodal Large Language Models (MLLMs) are now a fundamental piece of the current state-of-the-art of Generative AI. They help models handle data from multiple modalities with one single model, unlocking several highly promising use cases that were only but a dream earlier on.
But multimodality also takes machines closer to humans, as we are intrinsically multimodal through our senses. Thus, it was only natural that machines would follow suit eventually.
On our path to build Artificial General Intelligence, AGI, or Artificial Super Intelligence (ASI), multimodality plays a crucial role, as much of what has made humans the intelligent beings that we are today is due to our capacity to process data in multiple forms and make sense of it to navigate our world.
Therefore, multimodality also serves as a key functionality for machines to conquer the real world through robotics, so that they can see, feel, hear, and interact with our world in a similar way as we do.





