

Last updated: May 17th, 2024
Today, impact-wise, the differences between neural networks and AI are almost indistinguishable. Despite being just a part of the overall AI picture, frontier AI models, the most advanced models to date, are all neural networks.
But why? Today, we are diving deep into understanding the key principles that explain why neural networks have become so immensely powerful.
A Decades-Long Quest
Despite what you might expect, neural networks are several decades old. Precisely, they came into reality as approximation theories became popular.
Approximating an Unknown Function
We can measure an insurmountable number of events and observations in our world humans aspire to understand and leverage but can’t explain.
Nonetheless, finding clear explanations to the most critical questions about nature, physics, and the state of our world is necessary for us to advance as a civilization. Thus, scientists worldwide desperately search for answers.
For that, humanity follows the scientific method: observe certain behaviors and find the equation or function that explains them.
But what if where a way to unlock our capacity to uncover these unknown relationships and laws?
Over the past decades, researchers defined theorems like the Kolmogorov-Arnold Representation Theorem or the Universal Approximation Theorem, as a way to eventually find those hidden functions that map the causal relationships between a set of inputs and their outcome.
In other words, they defined different theoretical ways to find the relationship explaining that «when ‘x’ happens, ‘y’ happens» at scale. However, for decades, these theorems were just that: pure theory.
But with AI, things changed. In particular, AI has become a great way to find these patterns due to our AI systems’ great expressivity and attention to detail. In a nutshell, that’s what AI is: models that ‘study’ the training data and find key yet non-obvious patterns in data that help determine this observable yet hard-to-define relationship between them.
For instance, if we think about our friend ChatGPT, a Large Language Model (LLM), in principle, all it does is find the next word in the sequence given a set of input words. Indeed, humans can execute this very same function, as by learning languages, we have learned how words follow each other. However, we can’t put the statistical model that governs this relationship pen-in-paper.
At this point, we run into a conundrum. We know the theorem governing this relationship, and we have plenty of observable data proving such a relationship exists, but how do we unearth it?
Well, that’s precisely why neural networks exist.
Neural Networks, The Grand Piece in the Puzzle
Simply put, neural networks are how we parametrize the relationship between a set of inputs and outputs. In other words, by training this network, we find the parameters defining this relationship, whether that is:
- Using a set of house attributes to predict its price,
- leveraging a sequence of amino acids to predict how they fold to create a protein, as in AlphaFold 3,
- or using a sequence of text and predicting the next word in the sequence, like ChatGPT
One way or another, it all boils down to the same principle: finding the hidden relationship and parametrizing it (assigning a set of parameters that connect the inputs with the outputs) to use this network to predict the prices of new houses, new proteins, or new text sequences.
In fact, one could make the reductive claim that AI is nothing more than mappings between inputs and outputs, and you wouldn’t be very far off from an accurate and succinct definition.
The Core of Neural Networks
Probably the most essential component in neural networks or, to be more generalistic, Deep Learning, is a specific type of neural network known as the Multilayer Perceptron.
Initially “proposed” by Frank Rosenblatt and actually invented by Alexey Grigorevich Ivakhnenko, MLPs are considered the main element explaining Deep Learning’s success.
In fact, the relationship between Neural Networks and MLPs is so strong that, whenever you look for an image of what a neural network is, they tend to show an MLP as the one below as a default depiction, even though it’s not the only neural network in use today.
Below is a standard depiction of a shallow (1 layer) MLP, in which the relationship between the inputs and the outputs is defined by linear combinations of hidden units, usually known as ‘neurons.’
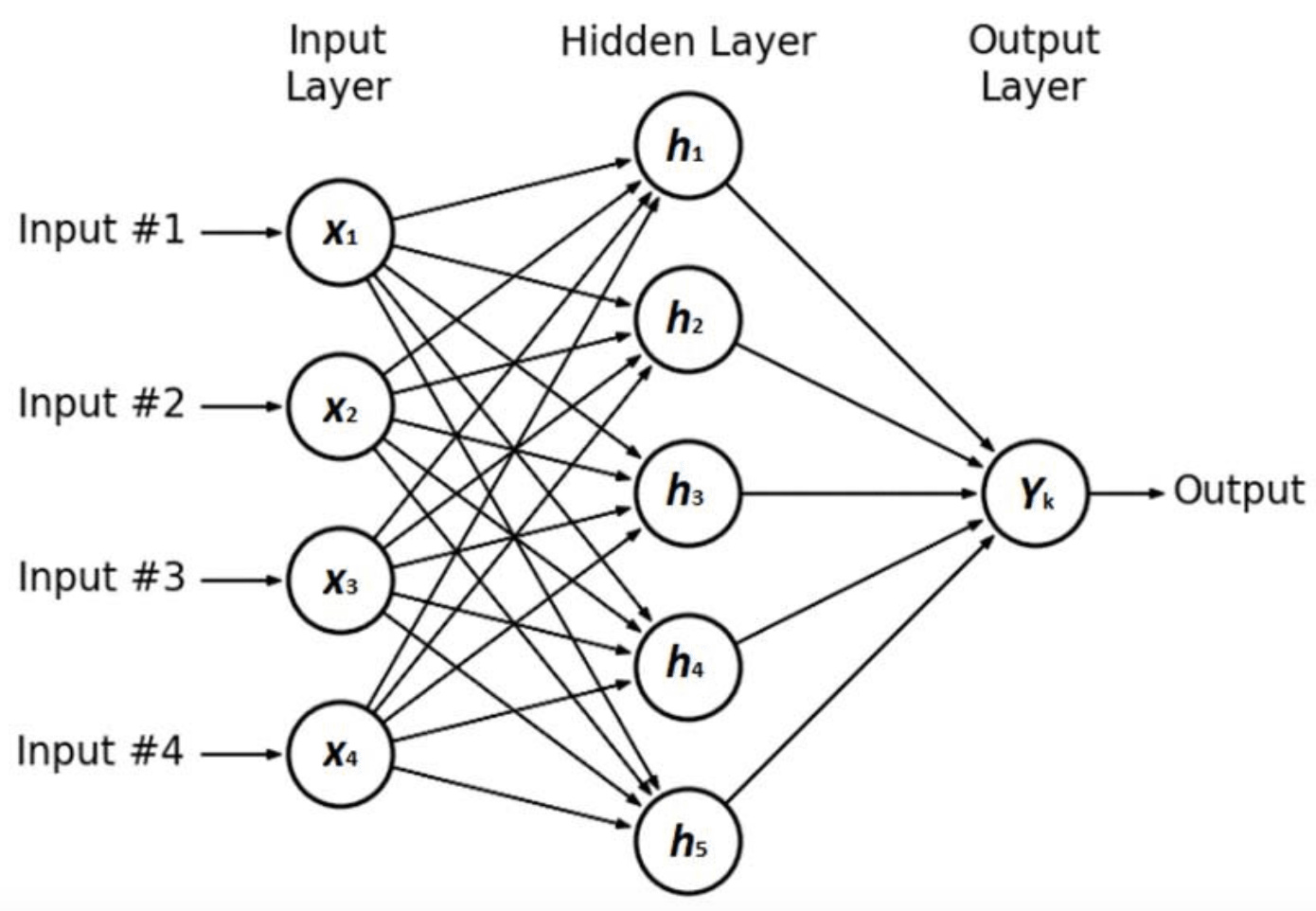
This can be considered the simplest neural network you can ever define, one that tries to find the relationship between the inputs and outputs through a single combination of the five hidden units in the middle. Specifically, each of the ‘hidden units’ depicted as ‘h1’ to ‘h5’ above performs the calculation below:
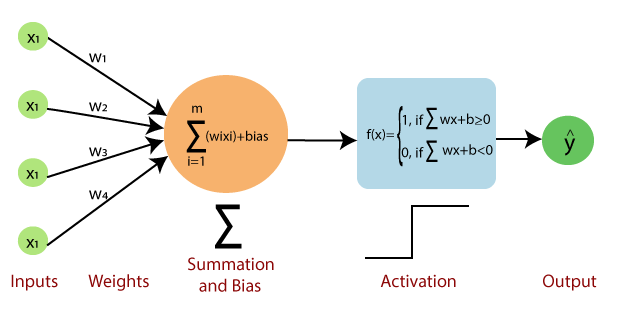
Broadly speaking, each neuron is a weighted linear combination of the inputs in the previous layer (in this case, the inputs to the model), but using parameters w1-w4 as the weighting elements plus a bias term.
Then, the entire calculation is driven through an activation function, a non-linear function that determines whether the neuron activates or not.
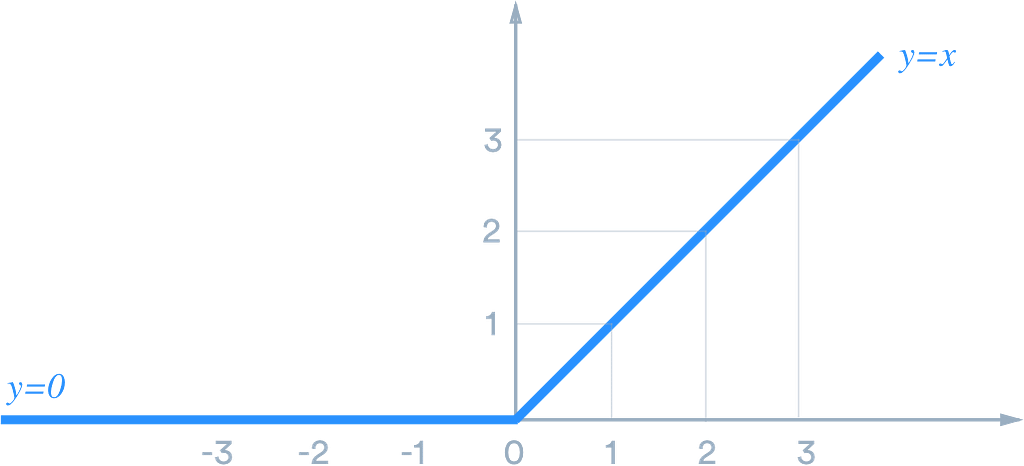
This activation function is crucial to help the model approximate non-linear functions. It also explains why they are called ‘neurons’, as they imitate the firing/non-firing behavior of brain neurons.
But why this architecture? The reason is the irresistible promise of the Universal Approximation Theorem.
The Principle to Rule Them All
As we mentioned earlier, we have known, for decades, mathematical theorems that promised to eventually find a way to find (or, technically speaking, approximate) these complex relationships in data, one of which is the Universal Approximation Theorem, or UAT.
The UAT is a formal proof “that a neural network with at least one hidden layer can approximate any continuous function to arbitrary precision with enough hidden units.”
In layman’s terms, a sufficient combination of neurons like the above eventually uncovers or approximates any continuous mapping between the inputs and outputs. In the case of ChatGPT, with enough neurons (which turn out to be billions and with other neural circuits such as the attention mechanism), one can effectively define a function that predicts the next word, given a set of previous words.
Now, I know all this sounds too abstract to see and understand. Adding insult to injury, humans can’t see beyond three dimensions, and current neural networks have thousands.
However, this theorem applies to all dimensions so that we can use a one-dimensional example from Prince’s great book Understanding Deep Learning.
Shallow Neural Networks
From here on, all graphs assume the activation function used is a ReLU. This is not relevant to understand the essence of how neural networks work so I wouldn’t bother too much, I’m just stating for mathematical rigour.
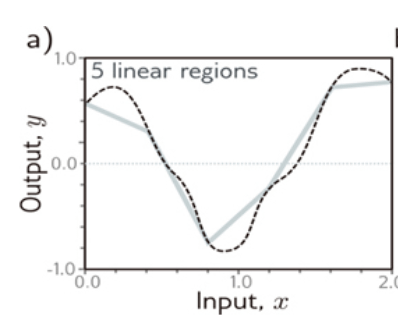
Imagine we have a pair of observations and outcomes ‘x’ and ‘y’ that we know occur in nature. For that reason, we know that there’s a function ‘f’ that models this relationship. As this is a toy example, we can actually draw this relationship, which turns out to be the one depicted by the black dotted line below. How do we find a function that approximates that highly irregular function?
Naturally, the whole point of neural networks is that we don’t know the black dotted line and thus we want to find it by approximating a sufficiently-good one through the neural network.
If we have four hidden units (aka four neurons), and we recall that each one represents a linear equation (as we saw above) and a corresponding activation function that decides whether the hidden unit activates or not, we can have a first try at combining these linear regions to approximate the curvy dotted function.
But if neurons are linear, how do we approximate non-linear functions?
With the activation functions. Each activation function plays the role of transition between different linear segments. For ‘n’ hidden units, we have at most (n+1) regions. In other words, the fact all neurons have an activation function at the end turns the global approximation function into a piecewise linear function. This is absolutely critical, as it allows the neural network to take non-linear shapes like the one we are discussing.
However, the previous image doesn’t look accurate enough, does it? Luckily, the theorem makes it very clear: we just need to increase the hidden units.
If we increase the number of hidden units to 10 and eventually 20 linear regions, we effectively approximate the original function one linear segment (neuron) at a time, as smaller linear regions allow us to fit the original function better and better.
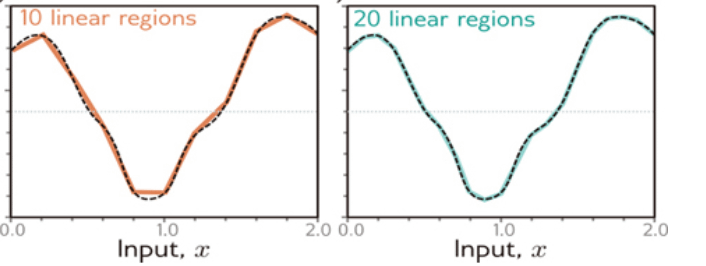
This is the essence of neural networks, and it’s why every AI model uses MLPs to approximate their respective functions.
Until now, I have described the ‘width form’ of the theorem, which states that you only need one single layer of enough width (number of neurons) to approximate the desired function.
However, in practice, what we eventually end up doing is stacking multiple layers instead of creating a very large one, a concept we know as Deep Neural Networks.
But why does this work better?
Deep Neural Networks
If we look back at the one-dimensional example earlier, the extent to which the neural network approximated the actual function was directly proportional to the number of neurons—hidden units—we had.
However, if we instead stack multiple layers, each new one essentially performs a ‘grid extension’ on each linear region in the previous layer.
In layman’s terms, for very complex functions, instead of generating hundreds or thousands of linear regions, we can stack as many layers as needed, depending on the granularity required, with a much smaller amount of required hidden units.
For example, for a two-layer network, the outputs of the second layer are replicated across every single linear region generated by the first layer, as shown below:
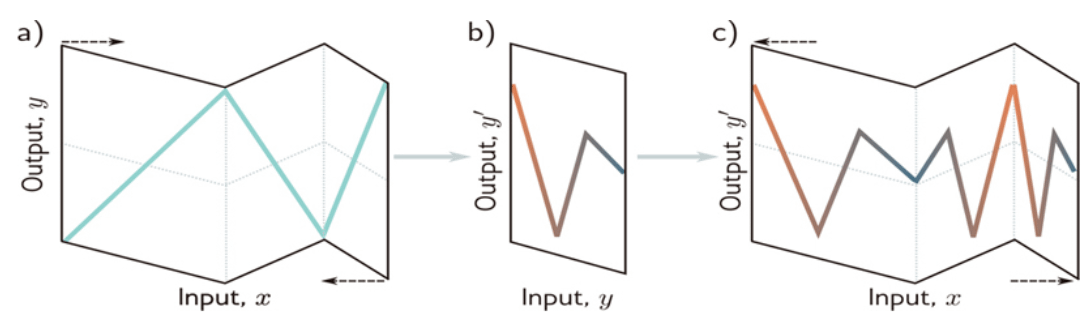
This is akin to ‘folding’ the different linear regions, one on the other, and drawing on top of them as if they were drawn on carbon paper.
In other words, the patterns that the new layer generates are applied to every single region in the previous layer, giving us the result to the right, where the pattern in ‘b)’ is replicated across all linear regions in ‘a)’ (‘a)’ and ‘b)’ representing the first and second layers of the neural network), and ‘c’ the final output.
Therefore, based on the theoretical intuition we mentioned, how many hidden units would a shallow network need to get to the function at point ‘c)’?
You guessed it, at least eight. On the other hand, with deep neural networks (more than one hidden layer) like the one we were talking about, at most, six hidden units, three per layer, are all you need to get the same output function while employing less compute.
Taking this into consideration, it’s no surprise than LLMs have gone deeper and deeper instead of exploding in width (number of neurons per layer) to the point that, today, frontier AI models have multiple dozens of layers.
And with this, you now have the key intuition explaining why neural networks have become so extremely popular over the last decade, to the point that every new AI discovery is almost guaranteed to be based in some way on this neural network architecture.
However, I think it’s best if we use an actual example.
Transformers as Proof of DNNs’ Success
Large language models (LLMs) are a very visual example of the success of neural networks and MLPs in particular. Specifically, most LLMs today are Transformers, a specific type of neural network.
We are beginning to see alternatives to the Transformer, like Mamba or Hyena, and also hybrids that combine Transformers with other architecture types. Still, Transformers are unequivocally the dominant architecture today.
Focusing on the former, although I suggest checking the original Transformers post for maximum detail, they combine two types of neural nets:
- The Attention mechanism, a mixing operator that allows words to ‘talk’ to each other and thus process the meaning of text sequences,
- MLPs, to apply non-linearity as the attention mechanism is totally linear. Without MLPs, models like ChatGPT would not be able to model non-linear relationships in language.
This gives us the Transformer block shown below.
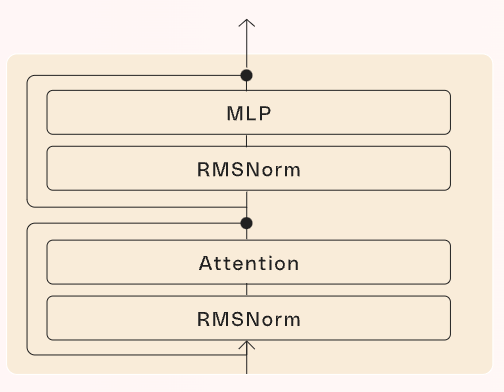
And how do we construct ChatGPT? We stack multiple of these blocks together, simple as that.
The Essence of AI
Today, we have reviewed neural networks, a seminal component of frontier AI, and how they have become crucial due to their powerful ability to model complex relationships between inputs and outputs.
Originating from decades-old approximation theories, they utilize mathematical theorems like the Universal Approximation Theorem, which states that neural networks with sufficient hidden units can approximate any continuous function.
Key components, such as Multilayer Perceptrons (MLPs), enable these networks to learn and predict patterns in data. This principle underlies the success of deep learning models, including Large Language Models (LLMs) like ChatGPT, which rely on stacking layers of neural networks to handle complex tasks efficiently.
The bottom line is that after reading this post, you now have second-to-none intuition as to why using neural networks is so powerful and essential to the development and progress of Artificial Intelligence.





