

Last update: April 23rd, 2024
If in the embeddings blog post we argued that embeddings were the foundation of all frontier AI models today, that is mainly thanks to the attention mechanism, the engine behind all Transformer models, which in today’s standards is the same as saying ‘all models’.
Ever since its initial presentation back in 2014, proposed by Yoshua Bengio, one of the Godfathers of AI, and especially after researchers at Google took its principles to create the Transformer, the world of AI has never been the same since.
All this peaked with the launch of ChatGPT back in November 2022, the model that you will agree with me changed the world completely – and forever.
And today, we are deep-diving into the world of attention for one single objective. By the end of this article I guarantee you will understand how models like ChatGPT, Gemini, or Claude ‘interpret our world’.
Why do we need Attention?
Succinctly defined, the attention mechanism is a system that allows words in a sequence to ‘talk to each other’.
To do this, it computes the similarity between tokens, a concept we describe as, surprise surprise, «attention», so that every word can update its meaning with the surrounding context that matters.
As the idea of computing semantic similarity is detailed in the blog post about embeddings, I won’t be getting into that detail here.
But what does that really mean?
Understanding the key intuition.
The first attention process always requires the entry sequence to be in the form of embeddings instead of plain text. If you wish to understand what embeddings are, I suggest you take a look here. Thus, for the rest of the article I’ll assume that you know what embeddings are and why they are so important for the attention process we are describing.
This may seem very complex at first, but with an example we will easily understand the whole process. Let’s say we have the text: “I walked down to the river bank.»
Although most words in that sequence are self-explanatory, there’s one that might be misleading: ‘bank’. The reason for this is simple, a ‘bank’ can refer to a financial institution where you store your money or the bank of a river.
For us, it’s easy to differentiate which one we are talking about, as we can read the rest of the sequence and figure out that we are referring to the latter. Funnily enough, although you’ve done it unconsciously, you have just performed the attention mechanism over that sequence, as you have updated the meaning of ‘bank’ with the surrounding relevant context.
In layman’s terms, you looked at the rest of the sequence and paid attention to the relevant words that allowed you to ‘update’ the meaning of the word ‘bank’ to the context of the present sequence. As the contextual information provided by other words like river is highly indicative, now we don’t doubt what definition of bank it is.
Thus, we arrive at a critical conclusion: The meaning of words isn’t only dependent on the word itself, but on its surrounding context.
So, in case it isn’t obvious by now, the attention mechanism we are talking about today does exactly that for AI models.
So, how does this process actually work?
Computing Attention
Once we have the input text sequence as a list of embeddings, we first project them using a specific set of matrices known as the Q, K, and V matrices.
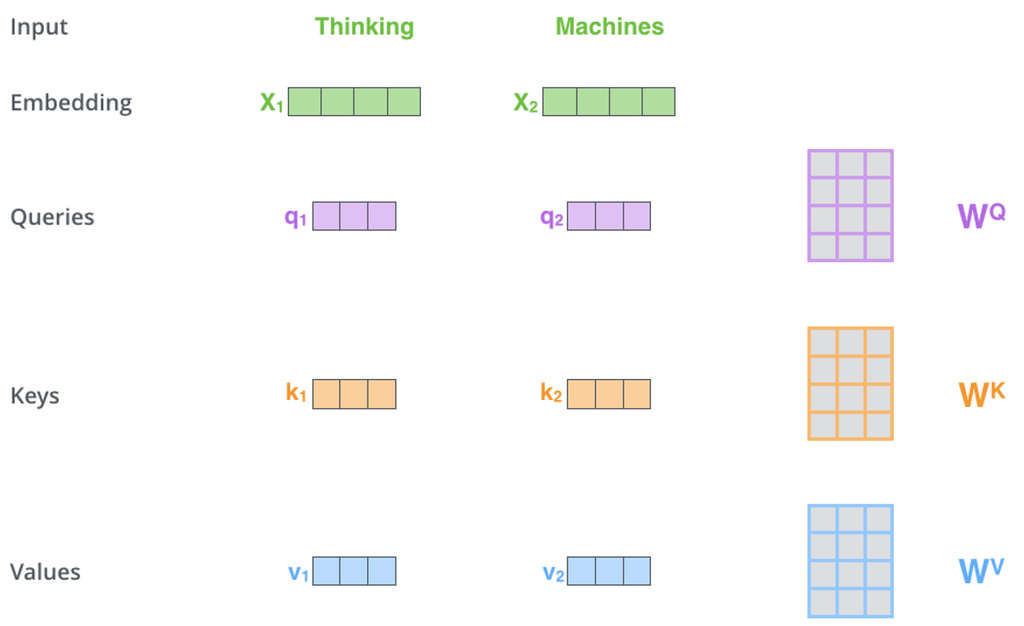
From now on we will be using Jay Alammar’s great illustrations (like the one above) to facilitate understanding.
This transformation turns the embedding forms of the words in our sequence into a set of three vectors:
- The query, representing «This is what I am looking for.»
- The key, representing «This is what I have to offer.»
- and the value, representing «If you pay attention to me, this is the information I will provide to you.»
Therefore, what the image above shows is how we obtain the three aforementioned vectors by multiplying each embedding with the Q, K, and Value matrices to obtain the Query, Key, and Value vectors for each embedding.
And with this, we are finally ready to perform the attention mechanism.
It’s all similarity computation
Today we are discussing standard (or vanilla) attention. Truth be told, since its introduction back in 2017, different variants of the attention mechanism have been introduced to try and reduce the computation requirements, with examples like Grouped-Query Attention used by models like LLaMa 3, or linear attention recently introduced and already used by Google in Gemini 1.5.
The functioning of these variants goes well beyond the scope of this article, but they are eerily similar to what we are discussing today.
First, we compute the attention scores for each embedding pair by multiplying the query vector of each embedding with the key vector of all other words.
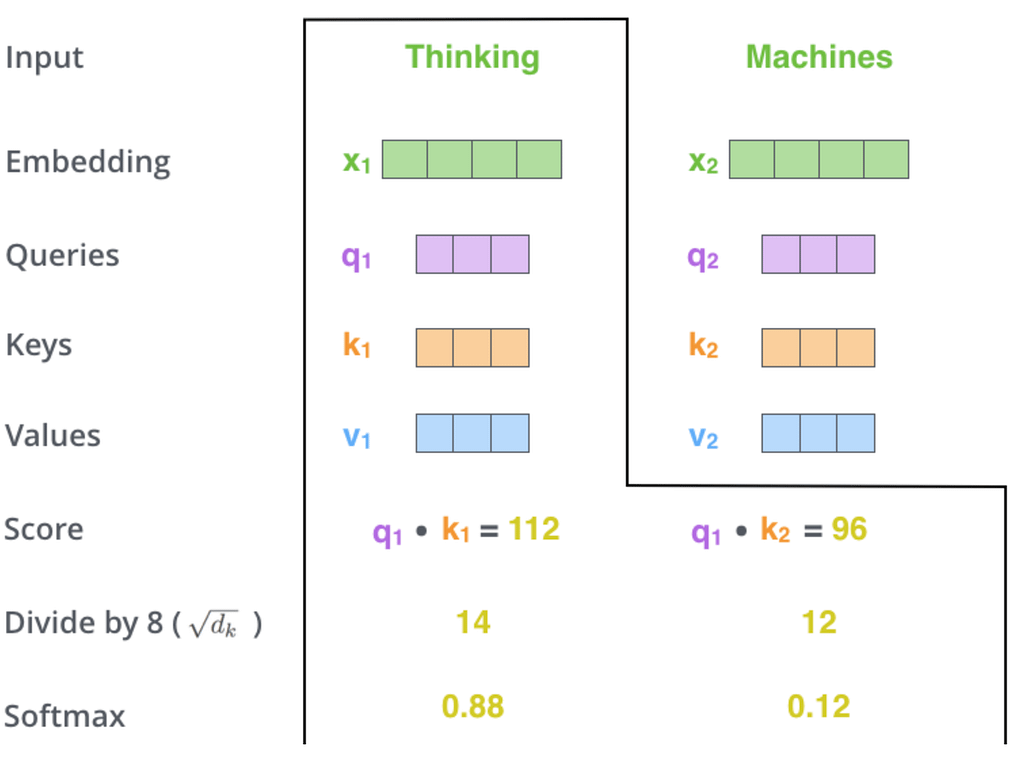
For every attention calculation, from the perspective of the word using its query, this calculation can be interpreted as ‘Hey guys, this is what I am looking for’. From the perspective of the word using its key vector, this multiplication is akin to ‘based on what your query is, this is what I have to offer to you.’
In more technical terms, when we multiply the query vector of one word with the key vector or another word, you get a scalar result we know as the ‘attention score’. As we described in the embeddings blog post, we can consider these embeddings as ‘lists of attributes’ of the underlying concept, and the Q and K vectors as projections of these attributes into a smaller dimension.
Therefore, when we multiply these two vectors, we are essentially comparing both words across the attribute dimension. In layman’s terms, we are computing the similarity between their attributes. Thus, if two concepts are similar in real life, like dog and cat, they should have similar attributes (similar numbers in their vectors) and, consequently, high attention scores between them.
Long story short, this ‘attention score’ indicates to the word represented by the query vector how much attention it should be paying to the other word.
Furthermore, for each word, once it has calculated its attention scores against the rest of the words in the sequence, it ranks them using a softmax to distribute ‘the percentage of attention it will pay to each one relative to the rest’.
In layman’s terms, the softmax step will classify all other words according to their «attention relevance» aka how important they are to that word in particular. Tracing back to the example “I walked down to the river bank» it’s more than probable that ‘bank’ will provide its biggest attention to the word ‘river’.
Then, with the other words classified, we use their value vectors, multiplied by their relative importance based on the softmax calculation (in the image above «Thinking» will pay 88% attention to itself while also paying 12% attention to «Machines»), to update the value of each word.
Put simply, now each word’s meaning not only encapsulates its intrinsic meaning, but also considers its surrounding context. In simple terms, after attention, this instance of ‘bank’ can no longer be a financial institution, it must be a river bank.
Now, take this operation and perform it several times sequentially and you get yourself an oversimplification of ChatGPT, as Transformer models like OpenAI’s famous model are basically this calculation we have just gone through stacked in multiple consecutive blocks, where the value representations (the embeddings) of every word in the input text sequences are recurrently updated over the concatenation of Transformer blocks.
I am purposely avoiding talking about feedforward layers, an essential piece in the Transformer block, because that will be discussed in an upcoming piece about the Transformer.
Thus, although with this information you can’t fully claim to know how ChatGPT works, the key principles, the essence, is right here. Nothing more, yet so powerful.
But we are missing one more thing you should know.
Multi-headed Attention
On a final note, I must mention that most models today don’t have one single attention head per block, but many. As we can see in the image below, this attention process is performed multiple times in parallel, with each one referred to as ‘heads’.
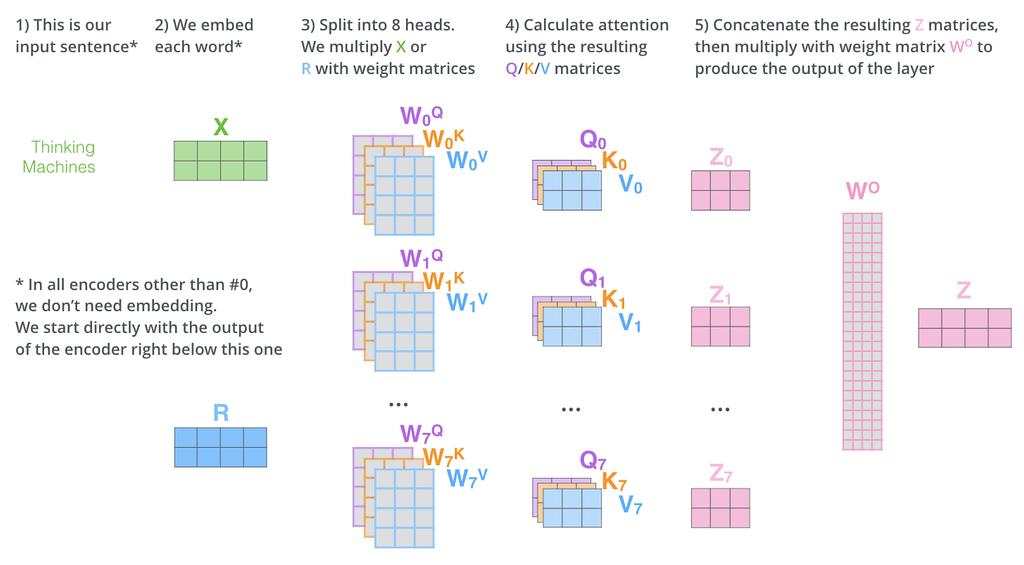
Beforehand, you might have wondered why projecting each embedding into three vectors. Besides the necessity to be able to perform the attention calculations, it also allows us to project each word embedding into equal-sized projections (smaller vectors representing each word embedding in a lower-dimensional space), each of which is run against its particular attention head.
Afterward, you concatenate the results and project them back into the original input size, so that the next Transformer block can do the same thing. In other words, instead of performing one single attention operation on each word in the sequence per block, you perform many in parallel.
This has two advantages:
- Multiple attention heads allow each head to specialize in detecting specific patterns, instead of relying on one single head to do all the processing.
- The concatenation of several Transformer blocks one over the other helps the model gain more and more intuition of the intricacies of the input text. That might be unnecessary for the short examples we have seen, but when the input sequence is hundreds of thousands of words long, which is something not that uncommon these days, the deeper your neural network goes, the better.
The Secret is No More
And just like that, you now have the key intuitions behind most frontier LLMs today. As you have seen, attention is embarrassingly simple, yet mind-bending effective, as ChatGPT or Gemini have proven to the world.
Wish to go back to the roots? Check my blog on what AI is in simple terms.





