

In the world of AI, both research scientists and engineers have consistently run against an insurmountable wall, the variance/bias trade-off.
And although a not-so-recent change in the AI paradigm known as foundation models might have alleviated the pains of such trade-off considerably, finding the sweet spot between the variance and bias of your model continues to be a huge part of the training process of AI models.
So, what is the variance/bias trade-off?
Changing the Approach to AI Forever
All AI models, in one way or another, learn from data. Specifically, their goal is to learn the underlying patterns of data, uncover them, and use them to make useful predictions on that same data.
At this point, you may be very tempted to force your AI model into memorizing the training data. But that is a huge mistake.
When I say that the models learn ‘patterns in data’ what they are really doing is learning the distribution of that data.
- In the case of language, with famous examples like ChatGPT, learning the distribution of data is akin to learning ‘how words follow each other’.
- For images, with examples like Stable Diffusion, the model learns how pixels are connected to create shapes of objects or concepts occurring in the world
But what mistake are we making if we force the model to simply memorize its data to the maximum extent? Well, here is where the variance/bias trade-off comes in.
Finding the Right Balance
If your model memorizes the data, it becomes extremely sensitive to even the smallest of changes. In statistical terms, that is akin to saying that the model has ‘high variance’.
On the flip side, if you don’t train your model enough on your data, the quality of the learned patterns will be insufficient and, thus, the accuracy of its predictions will be poor. In other words, even the biggest and most relevant changes to the data won’t affect the model, which will still execute poorly. In that case, we say the model has a ‘high bias’.
This trade-off is very well understood using the following image:
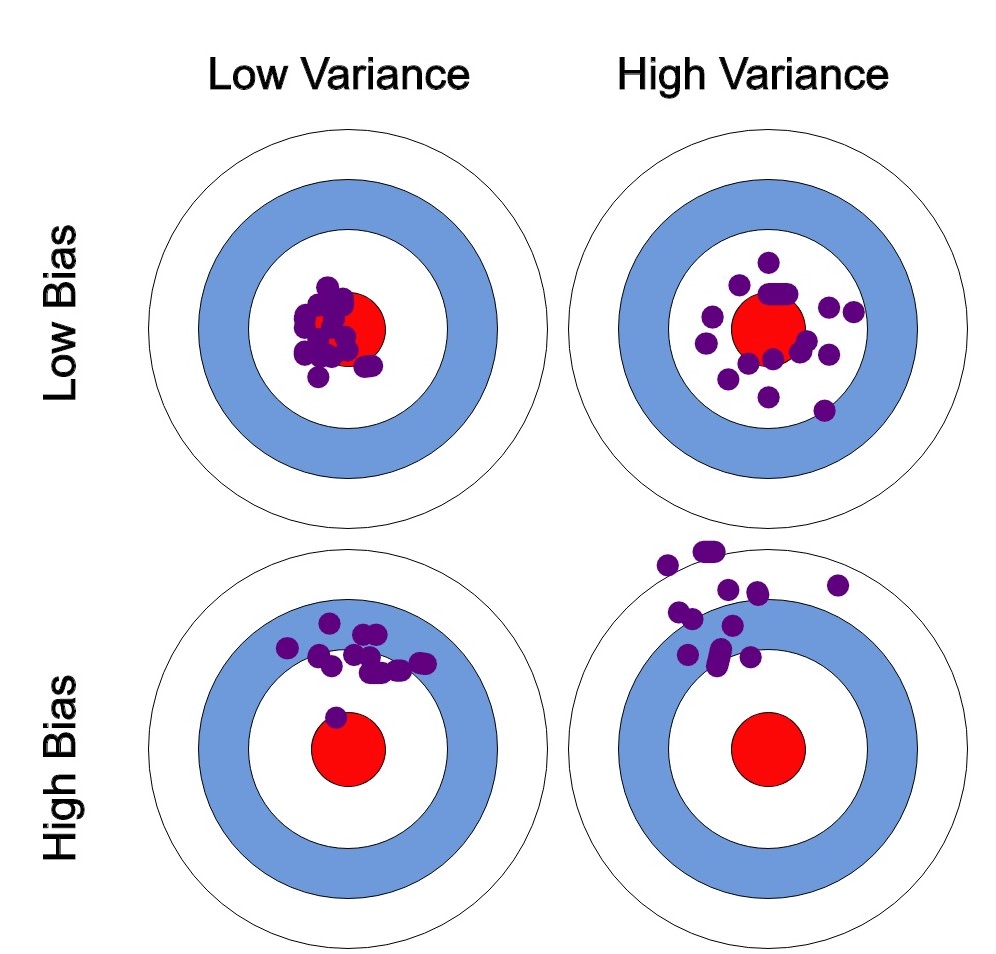
If your model has high variance with low bias, the model will tend to approach the correct answer (illustrated as the red circle in the middle) but very slight changes to the body mechanics of the archer cause massive drifts in the result. This means that the model is extremely sensitive to input changes, as it has basically memorized the training data to the point that anything that doesn’t resemble almost perfectly the training data is considered ‘unknown’.
When we are at this stage, we say the model is ‘overfit’.
At the other end of the spectrum, if your model has high bias with low variance, your model will rarely approach the correct answer (only once in the image above) and no matter the changes the archer does to its body mechanics, he/she will still miss most of the time (one could argue that in this scenario, right predictions are almost random). In this scenario, as the model hasn’t learned the patterns of the data, even though the variance in the predictions is small (explaining why most dots are close by) the accuracy is horrible.
In this scenario, we say that the models are ‘underfit’, as the model hasn’t fitted in the slightest to the training data, akin to saying it has not learned anything from it.
So where should we be aiming?
Obviously, we should aim at something in the middle, or ideally, the low variance / low bias scenario, where the model has high accuracy (low bias) with low memorization rate of the training data (low variance). Here, the model behaves in a predictive way and is accurate.
The truth?
That’s an extremely hard place to land on. Most of the time, if not always, your model will lie between both worlds and the AI engineer’s role is to strike the best balance possible between variance and bias, hence the name of the ‘variance/bias’ trade-off.
So how do models behave in this ‘in-between’ area?
If your model is more skewed toward high variance while having low bias, that implies that your model has a very good knowledge of the distribution of the training data and immediately reacts to the changes in the input data (that matter).
However, that means that your model is also more sensitive to out-of-distribution shifts. In layman’s terms, if the new data the model sees is ‘too different’ from what the model has seen during training, its predictions will be most probably poor.
The reason for this is that, even though the model reacts to changes in data which is expected, unless this is paired with good and generalized knowledge of the data (low bias), the model will tend to behave too chaotically.
For example, let’s say that you’ve trained the model with a dataset of images exclusively portraying orange cats.
In this scenario, to the eyes of the model, it will have learned various patterns: how cats look, what poses they have, and so on. But, importantly, it will have arrived at the inevitable conclusion that all cats are orange.
So what do you think will happen if you show the model a brown cat? According to the model, that is not a cat, period.
This example alsho showcases the importance of using appropriate data, aka data that represents the world accurately and in a non-biased way.
This is of course a very extreme example, but the point still stands, if you force a model to memorize the data instead of actually learning its underlying patterns, even the slightest of changes (much more subtle than the example I gave) will cause the model to arrive at wrong predictions.
On the other extreme, if your model is more skewed to having ‘high bias’, akin to not giving it enough time to learn the data, the model won’t learn any meaningful patterns, which means its predictions will be useless.
So what does it mean to strike the right balance? A good model will be one that can accurately predict based on the data, but is still adaptable enough to work well with new data.
The example below showcases the three examples:
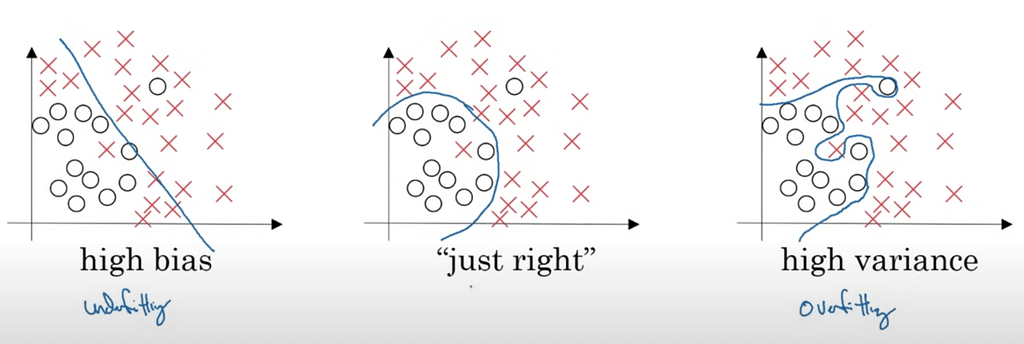
As you can see above, the high-bias model (underfitted model) can’t really decide to what class each data point belongs to. It’s the worst possible model.
In high variance, the model fits the data perfectly, correctly classifying all the data points. But if you find a dubious example close to the border between the two classes where we don’t know if it’s an ‘x’ or a circle, what option do you choose with that model?
Although this model behaves well with your training data, it’s incapable of generalizing to new data that doesn’t follow the memorized patterns in the training data, aka being incapable of predicting the correct way with new data that is slightly different from the data seen during training.
The one in the middle finds the sweet spot, as even though it will have some mistakes (like the circle that is on the wrong side of the border) the model has still realized that data points close to the bottom-left side of the graph are usually circles (which is palpably true and it’s a good pattern to learn).
And the real question is, where do LLMs land in this?
The Sweetest Spot
It’s hard to define, but one could make the case that they are heavily underfitted.
The reason for this is that most LLMs can be considered foundation models, models that have reached a point where they are capable of deep generalization, even at data and tasks like nothing they have seen before!
In other words, they tend to have low variance, meaning that they are well-responsive to many different changes. Read here for an in-depth yet digestible explanation of what foundation models are. This is easily understood if we think about the human language.
It’s almost guaranteed that the way you and I communicate with ChatGPT, or any other LLM, will be very, very different. Still, the model responds similarly to similar requests, no matter the format they have been received.
However, saying that LLMs are underfitted could be misinterpreted, because that could be understood as saying that they don’t predict things as they should. However, even though they are low variance, they still have pretty low bias too, allowing them to be useful most of the time.
What’s more, although I’ve not seen anyone claim this, foundation models could be the first time we have actually had a low variance/low bias AI model. However, it’s safe to say that in the variance/bias spectrum, they are generally low variance and low bias, although they can exhibit high bias (when performing poorly in certain tasks) and high variance in many cases (especially when fine-tuned to very specific tasks too much).
But why?
Well, because even after having managed to learn the distribution of language, which is one of the hardest functions one could approximate, LLMs are still massively underutilized in practice.
In other words, out of the billions of parameters they have, only a small fraction (a very, very small one in some cases) actually run for a certain prediction.
This is the reason why researchers these days run many more epochs of the data (entire runs over the training data) to improve model performance and still not going anywhere near to overfitting the model (unless the data is too specific).
Consequently, even though you run the entire network for every single prediction, only a small set of neurons actually matter in each prediction, making the process incredibly inefficient.
Still, they are the best models we have today, period.
Still a Trade-off, Much Less of a Problem
In this post we have reflected on one of the most complex tasks in AI today, finding the sweet spot between bias and variance. Thanks to foundation models, this trade-off is much less of a problem these days.
However, even our most powerful models can still suffer the effects of the trade-off, mainly:
- Overfitting Risks: When fine-tuning on small or highly specific datasets, there is a risk of overfitting, which could increase variance if not managed properly.
- Hallucination and Errors: LLMs can still make errors, such as generating plausible but incorrect or fictional information (hallucinations), especially in tasks requiring high factual accuracy.
- Computation and Resource Intensity: The training and deployment of LLMs require significant computational resources, which can be a barrier in terms of accessibility and cost.
Thus, it’s still very relevant to keep this trade-off very much top-of-mind whenever you are faced with the challenge of building an AI system.
Want to trace back to the roots of AI? Read here my simple introduction to AI.





