

Last update: April 17th, 2024
This article is part of a series that aims to describe how our frontier AI models are created in easy-to-understand terms, with today’s topic being Transformers, a seminal component of these models. In particular, this piece assumes the reader understands what embeddings are and how the attention mechainsm works. Otherwise, I deeply suggest you read first the previous two links to ensure this article is understood.
Decades from now, we will look back and still be amazed at how the Transformer architecture changed the world of AI and, eventually, every single industry and science known to humans.
In fact, all the best models everyone knows the name of can be traced down to the research paper, back in 2017, that introduced the Transformer. ChatGPT, Gemini, Claude, Sora, Stable Diffusion… you name it.
The impact and influence of this architecture is so profound that Andrej Karpathy, one of the most famous AI researchers in the world, summarized the job of AI engineers and research scientists as ‘touching everything except the Transformer’.
But what is it, and why it has become completely ubiquitous in the world of AI today?
Word of caution, I will be referring mostly to decoder-only Transformers, aka Large Language Models (LLMs) like ChatGPT or Gemini. In other words, Transformers whose objective is to generate a output such as words.
A Scalable Beauty
Back in 2017, a group of researchers at Google Brain were fiddling with this idea known as ‘attention’. Presented back in 2014 by researchers among whom was the famous Yoshua Bengio, this concept introduced a really elegant way of processing – understanding – sequence data.
Attention is a Limited Resource
Sequence data is data that is distributed, you guessed it, sequentially. For example, words are written sequentially to assemble sentences. Sequence data can encompass almost any modality, not only text, but also images, video, or even audio.
Although thoroughly explained in my other recent post aimed specifically at demystifying this seminal operator known as the attention mechanism, the idea is that this operator has proven to be unbeatable when it comes to sequence processing and, considering that a huge amount of our data can be considered a sequence, this meant that this operator has become an absolute standard in data processing.
Whenever I refer to ‘data or sequence processing’ what I’m referring is to the capacity of a machine to understand, or comprehend, what the data semantically conveys. With text, that would be understanding what it’s describing.
However, when attention was first introduced, the state-of-the-art at the time were Recurrent Neural Networks, AI models that processed data in a sequential manner (in the case of words, that meant one word at a time). Sadly, this caused the process to be highly unscalable.
But that changed with the presentation of the Transformer architecture.
Attention: From Transformers to the World
Although I will use ChatGPT as reference for my explanation, the attention mechanism can be applied – and is universally applied – to many other modalities besides text, like images, video, audio, music, speech… you name it.
Thus, the simplest way of explaining how ChatGPT processes and understands your inputs is through the recurrent application of the attention mechanism over multiple Transformer blocks.
But what is a Transformer block?
Blocks over Blocks
When thinking about models like ChatGPT, for a given sequence, they recurrently predict the next word.
Word of caution, what they really predict is the next ‘token’. In the case of text, tokens are generally represented by a set of letters, usually between 3 and 4. Sometimes, however, you may see complete words represented as tokens, depending on the degree of usage they have in a particular language.
For the sake of explanation, for the rest of the article just assume that every token is a complete word.
But how does it do that? As mentioned earlier, by concatenating Transformer blocks. But what are these blocks? As shown below, a Transformer block, sometimes referred to as the ‘Transformer layer’ has four distinct components.
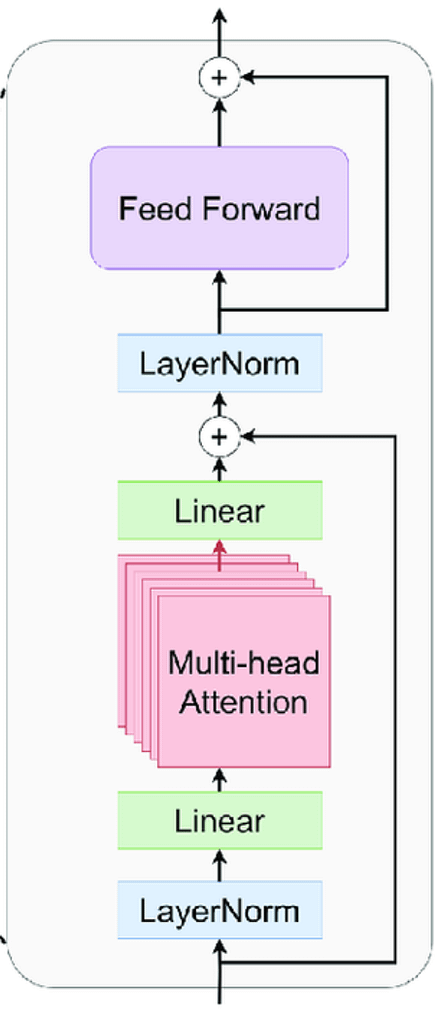
- Multi-head Attention layer: Here is where the magic really happens, where the attention mechanism is applied to all words in the sequence.
- Normalization (LayerNorm): To guarantee training stability, the activations obtained from the attention layer are normalized to avoid, among other things, the vanishing/exploding gradients problem.
- Linear: These are linear projections that are performed to ensure the dimensions of the embeddings are the required ones. For example, the first linear layer (depicted at the bottom) is used to project the word embeddings into the sizes that every attention head requires.
- Feedforward layer (FFN): Increases the dimensionality of the distinct embeddings to unearth the hidden nuances of text. As explained in the embedding’s post, AI models treat words as vectors of numbers, where each number represents an attribute of that word. FFN layers increase the amount of numbers these vectors have – sometimes referred to as ‘channels’ – to increase granularity and allow the detection of more fine-grained information.
One element not shown in the previous image is the positional encodings. One of the reasons (if not the biggest one) why Transformers became the golden standard is due to their extremely parallelizable nature that made them the perfect match to GPUs, the standard hardware for AI models. The reason for this is that the entire sequence is introduced into the network at once. In layman’s terms, instead of processing the text sequence one word at a time, all words are inserted simulataneously.
This begs the question: How does the model then know the order of the words in the sequence, which undoubtedly still matters? To solve this, we add positional information to every word embedding, so that the model is ‘aware’ of the order of words despite being processed in parallel.
But what is the output of these blocks and what is the effect?
After the sequence is processed by the block, the words (remember, they are in vector form, aka embeddings) are ‘updated’ with information provided by other words in the sequence. In simple terms, this means that Transformer blocks ‘mix’ the words in the sequence to allow them to ‘talk’ to each other and update their meanings with respect to the rest of the words in the sequence.
For example, for the input sequence «I thought about hitting the bat with my bat but I didn’t», how does the machine know what definition of bat is represented by each word?
We know that the former refers to the animal and the latter to the baseball club by paying attention to the surrounding context in each case. Thus, by performing the attention mechanism, the machine does essentially the same (for instance, the second instance of ‘bat’ will pay a lot of attention to ‘hitting’ to realize it a baseball club that can be used to hit something).
However, one Transformer block will not do the trick, so we actually stack many of them in order to create the models that actually arrive at your hands.
But wait, how do we actually get new words from these networks?
Assembling a Decoder-only Transformer Model
Now that we know how input sequences are processed (with the Transformer blocks) and how to obtain an output (softmax layer) we can actually draw the entire network:
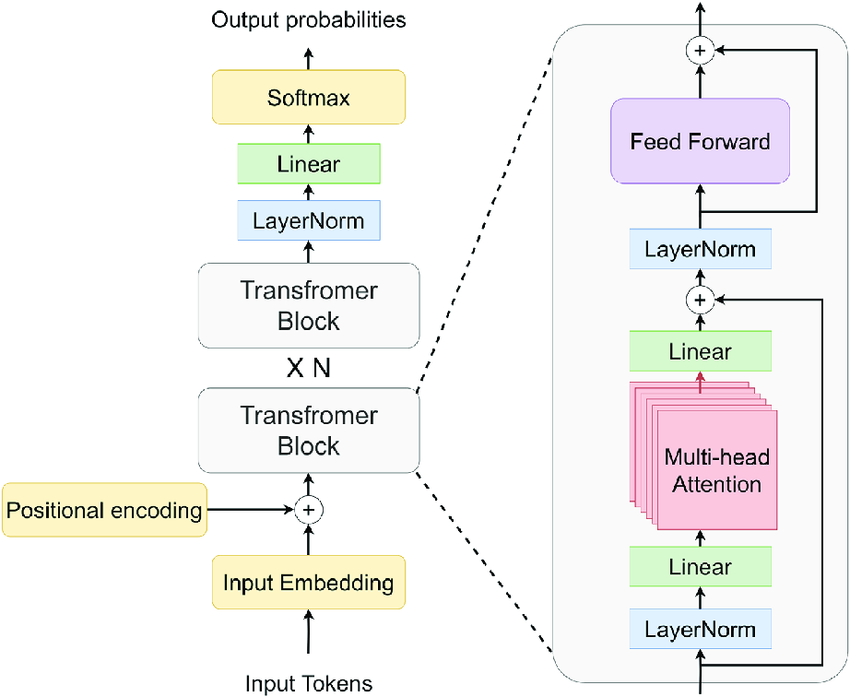
Consequently, how do we actually build a Transformer?
Well, at this point it’s quite easy. We simply stack Transformer blocks like there’s no tomorrow, and finish with the softmax layer we recently explained (the layer that outputs the list of possible word continuations to the provided sequence).
You may seem that I am suggesting that Transformer blocks are added with no control. Well, I mean it. As proven by recent research carried out by Meta and MIT, we can actually eliminate most of the future layers of a network with no accuracy loss. So yeah, we are basically accumulating Transformer blocks in promise of better performance with little to no control.
However, one more thing is required to actually build a Generative Pretrained Model, the base of ChatGPT (the most advanced version of this base model is GPT-4):
The embedding matrices.
Decoder-only Transformers
If we recall the beginning of this piece, I mentioned that most LLMs today, if not all, are decoder-only Transformers. What I mean by this is that the original Transformer presented in the «Attention is all you Need» paper was formed by an encoder and a decoder, and current LLMs only have one piece of that original architecture.
An encoder is in charge of taking an input sequence, like a word sentence, and transform it into a sequence of embeddings that would then be handled by the decoder and regenerate them back into text, this time outputting the next word in the sequence.
The main difference between an encoder and a decoder, besides the last layer, is that decoders perform masked attention. In other words, words can only ‘attend’ to words appearing previously in the sequence, not the future ones. For that reason, LLMs are often referred to as autoregressive Transformers.
However, as it turns out, all the encoder efforts to process the sequence aren’t really required for most next-word predictions. Hence, to avoid unnecessary computation, the encoder is discarded.
But then, how do we transform the input sequence into a series of word embeddings (vectors), necessary to process them through the decoder (the actual LLM) if we don’t have an encoder?
And the answer is the embedding matrix. This embedding matrix, sometimes referred to as ‘look-up matrix’, is a matrix that automatically retrieves the word embedding assigned to each token.
To comprehend their value, we must actually review the complete process. For example, what happens when I send ChatGPT the sequence «The fox jumps over the lazy…»?
- The sentence is first tokenized. What this means is that the sentence is ‘chunked’ into tokens. It’s actually not that easy to explain, but for the sake of simplicity let’s assume that 1 token equals 1 word. Thus, the result is [‘The’, ‘fox’, ‘jumps’, ‘over’, ‘the’, ‘lazy’]
- This tokenization process also assigns an integer value to each token. This integer represents the number assigned to that token from the LLM’s vocabulary.
- Using this integer, we now proceed to the embedding look-up matrix, locating the row pertaining to each token (based on their assigned integer) and automatically retrieving their corresponding embedding. Consequently, every token in the original sequence gets assigned its particular word embedding.
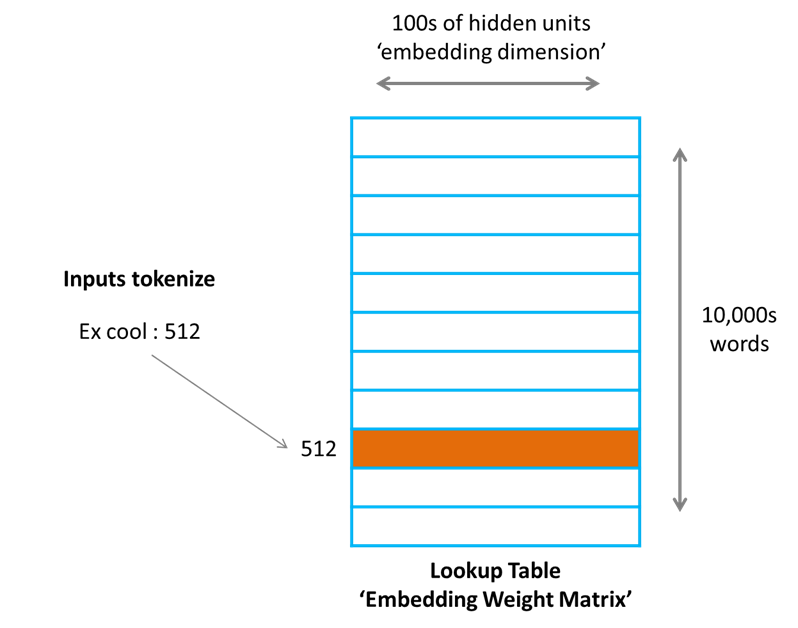
- At this point, we are ready to send the sequence, now converted into a series of word embeddings, into the actual set of Transformer layers. But before we do so, we must add positional encodings to each word embedding. As all tokens are processed in parallel, we need to add some positional information to them so that the model is ‘aware’ of the real order despite simultaneous computation.
- The sequence gets processed and through the Softmax layer (depicted on-top in yellow in the previous image) we output the full vocabulary list representing the probability distribution over the next word.
- Finally, using various different methods, we sample from that distribution, usually choosing at random one of the top-k options.
- Et voilà, you got yourself the next token in the sequence, which in our example would most probably be ‘dog’. Then, we group the entire sequence (now including the new word) and reproduce this whole process again to generate the next token.
Regarding point 6, be aware that the inverse of point 3 has to be done. In other words, if point 3 turned our words into embeddings, the output embedding matrix does the opposite, it takes the new embedding and turns it into a natural language word, which is the actual word you see on your ChatGPT interface.
Pretraining this model over a huge text corpora is what gives you the base model, like GPT-3.5 or 4 in ChatGPT’s case.
Turning Transformers Base Models into Chatbots
In this article we have reviewed the entire idea of Transformers, the architecture that underpins a great deal of progress in the AI space for the last 7 years.
On a final note, please be aware that the resulting model of the process we just described would not be ChatGPT. As we will cover in a blog post specifically on Large Language Models, two additional fine-tunings, named SFT and alignment, have to be made to obtain the actual product millions of people use today.
But more on that another day.





