

Last updated: April 23rd, 2024
There are few things in the world of AI today more crucial than embeddings.
Simply put, they are the foundation on which most models today, ranging from ChatGPT to Sora, stand on. Without them, there are no foundation models and no Generative AI, period.
But what are these elements, and why are they so crucial?
Today we are diving deep into the world of vector embeddings so that, by the end of this piece, you will have a clear notion of their importance to today’s frontier AI.
Please, draw me a rabbit sir
Imagine I ask you to draw an animal. Unless you’re an artist, your sketch might look something like this (mine definitely would):

What animal is this? Probably, you are going to guess it’s a rabbit. But what aspects of the drawing hinted you this could be a rabbit?
Maybe… the ears? The tail? And maybe the teeth and rounded nose?
Despite the poor execution, certain attributes still reveal it’s a rabbit. That’s because, in the human mind, we have a representation of ‘what a rabbit is’.
However, unless you’re Leonardo Da Vinci, your lack of talent might force you into drawing only the key attributes that distinguish a rabbit from any other being in the animal kingdom. Most probably, you will choose the universal attributes that everyone assigns to rabbits, like the goofy ears or the slightly overwhelming teeth.
But why am I telling you this?
Well, because I have indirectly explained to you what an embedding is. Probably you aren’t fully aware of what’s going on right now, but you will in a minute.
The Concept of Representation
As much as we would love to, the reality is that machines are totally different ‘things’ compared to us. They simply don’t see or comprehend the world in the same way we do.
In fact, it’s quite extreme. Humans see the world in various ways, through our senses, through our experiences, and even through the lens of our very own brain predictions, as the theory of active inference proves.
On the other hand, machines can only see numbers. Ones and Zeros to be precise. Thus, if we want to teach a machine what a ‘rabbit’ is, first we must overcome the following obstacle:
How do we represent a rabbit as a number?
At first, if you are a little bit tech-savvy, you might suggest ‘as an image’. And you would be right, as an image is a set of pixels (numbers from 0 to 9 over three color channels, red, green, and blue).
Sadly, an image won’t work for one simple reason: you can’t compare them. But compare what?
It’s simple. While machines differ a lot from humans when it comes to ‘seeing’ the world, they interpret it in a very similar way: applying similarity.
Nonetheless, even though you aren’t consciously doing this, the human brain is continuously comparing stuff. For every new unknown object or thing you come across, your brain automatically shifts into ‘similarity’ mode, and will be confident or skeptical about the nature of what it’s perceiving depending on how similar it is to other things it has seen in the past, aka its experience.
Well, this similarity idea, referred to as ‘relatedness’ by OpenAI, is the foundation principle used by current AI models to ‘understand our world’.
But how do you combine both ideas, having things represented as numbers and in a format that can be comparable?
And the answer is, you guessed it, embeddings.
Embeddings are to AI What Proteins Are to Humans
Simply put, embeddings are the bridge between our world and machines.
In practice, they are vectors of numbers that represent an underlying concept. Importantly, they are what we define as ‘dense’, meaning that the numbers that form the vector aren’t random, but intend to capture the attributes of the object, being, or thing they represent.
To understand this, we must go back almost 10 years from now.
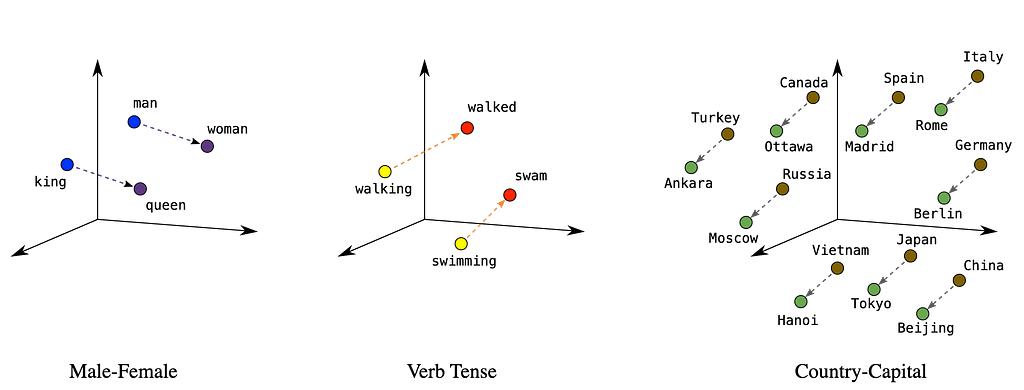
‘King – Man + Woman = Queen’
Probably one of the most famous equations in history, «King – Man + Woman = Queen» pretty much sums up one of the most relevant discoveries in the history of AI. Dense embeddings were officially introduced by Google’s word2vec (Mikolov et al) back in 2014.
This was the first time we had managed to turn words into vectors and, more importantly, achieve something incredible in the process: gaining the capacity to perform arithmetics with words.
For example, one of the most visual examples was the aforementioned equation, whereby subtracting Man’s vector from King’s vector and adding the Woman’s vector, the resulting vector was none other than ‘Queen’, which meant that, indeed, the numbers in the vectors carried out the meaning of the underlying concept.
But how can we get a better, or tangible, intuition of what embeddings are? Funnily enough, with sports.
From Rabbits to Madden
Although it is a little bit more complicated than this, think of each number as an attribute that indicates the model about a certain aspect of the underlying concept, like its color, its shape, or the length of its ears for our rabbit friend.
Put together, all attributes must portray a semantic description, as accurately as possible, of the original ‘thing’. But unbeknownst to many reading this, this is nothing new, as representations of this nature are everywhere.
For example, if we think about football players in Madden (or FC24), athletes are represented as a set of physical attributes, as represented in the image below (speed (SPD), Throw power (THP), deep throw accuracy (DAC), etc.).

These attributes are so tailored to each player, that most enthusiasts don’t even need to look at the card to know that was Patrick Mahomes.

You are getting the gist, right? Embeddings are simply a numerical way of representing the same concept, so the numbers must speak to what the underlying element is.
But what makes this vector representation so crucial? Well, the reasons are twofold:
- Need. As we discussed earlier, machines only see numbers, so some sort of numerical representation is mandatory anyway
- Computing similarity. As we are representing things in a high-dimensional space (dimensions are the count of numbers a vector has) we are giving each element a place and direction in space.
Focusing on the latter, thanks to the fact that we now have things represented as vectors, we can calculate the distance between them.
And here’s the key intuition behind embeddings: if these vectors gather the main semantic attributes of the underlying elements they represent, vectors that are closer together mean they represent semantically similar concepts.
Proximity isn’t the only crucial thing, but also the direction of the vector. In other words, two similar concepts must have vectors that are close in space and with the most similar vector direction possible.
Circling back to our rabbit, its vector representation will capture his/her ‘essence’, and place the rabbit in the vector space in a position where other rabbits will be located too, or close to other related animals like hares.
But this principle, closely related elements will be closer in space, applies to every concept in our world; even if they represent non-physical things like names of countries and their capitals:
But we still haven’t answered the question. Why are they so important in today’s AI?
From embeddings to ChatGPT
Although I won’t get into too much detail for the sake of length, almost all frontier AI models today, aka the most advanced and powerful models, are abased, technically speaking, on the attention mechanism.
The attention mechanism computes the similarity between tokens (the embeddings of words) in a sequence. For instance, in the case of text, assuming each word is a token (each word has its own embedding) it computes how much ‘attention’ each word should be paying to each other word.
Verbs to nouns, adverbs to their verbs… and so on. That way, the model builds an intuition of what the text is saying. In other words, the attention mechanism relies heavily on embeddings to work.
ChatGPT, Gemini, Dall-E, Stable Diffusion, Sora, Claude… you name it. All of them, and I mean all, are based on the same architecture, the Transformer, an architecture whose sole role is to exercise the attention operator over the input sequence.
Consequently, if ChatGPT requires the attention mechanism to work, and the attention mechanism needs embeddings to work, then it’s clear that without embeddings, nothing you have seen in AI over the last few years would have happened.
It all traces back to embeddings
In summary, embeddings are the foundation of all foundation models today, and by extension, of almost every single breakthrough taking place in AI today, especially in the field of Generative AI.
But what is AI?
If you wish to back to the roots of everything in an easy-to-understand manner, I deeply encourage you to read this other blog I recently wrote. If you already know what AI really is, I highly recommend you proceed to the next blog about the attention mechanism.





